



پیشبینی عملکرد شبکه برای رسیدن به طراحی بهتر ظرفیت، در شبکههای تلفن همراه بسیار مهم است. یکی از مشکلات کلیدی، پیشبینی ارزیابی بازده طیفی در شرایط باری بالای شبکه است. براساس تجربه، عامل اصلی که عملکرد شبکه و بازده طیفی را تحت تاثیر قرار میهد، شاخص کیفیت کانال (CQI) است. در این مقاله، سعی شده است با استفاده از پیشبینی CQI بوسیله شبکه عمیق عملکرد شبکه موبایلی همراه اول را بررسی نماییم. به سبب آن که پیشبینی شاخص کیفیت کانال عامل کلیدی برای عملکرد شبکه و بازده طیفی میباشد و از جهتی به منظور بهبود پیشبینی، استفاده از ویژگیهای مناسب برای شبکههای یادگیری عمیق تاثیر بسزایی دارد، ویژگیهایی نظیر (باند فرکانس، بلوک منابع فیزیکی (PRB) در سلولهای اطراف، تعداد سلولهای اطراف در شعاع 2.5 کیلومتری، ظرفیت ترابری دانلود و آپلود[1] و استفاده از مدولاسیون مرتبه بالاتر[2]) نیز به عنوان ورودی به شبکه یادگیری عمیق انتخاب شده است. در نهایت مدل ارائه شده برای پیشبینی شاخص کیفیت کانال با دقت 96 درصد برای مجموعه داده سلولهای همراه اول به دست آمد.
کلیدواژه: مخابرات سلولی، ظرفیت، هوش مصنوعی عمیق، CQI[3].
![]() طراحی بهینه ظرفیت شبکههای تلفن سیار، همواره یک چالش برای طراحان شبکه در دهه گذشته بوده است. بعلت آنکه ترافیک شبکههای تلفن همراه به طور تصاعدی در حال افزایش است، با وجود آنکه نرخ رشد شبکههای تلفن همراه به عوامل متنوعی وابسته است، اما ادعا شده است که به صورت میانگین در هر دوسال ترافیک دو برابر شده است[1]. این سرعت توسعه منعکسکننده قانون مور است. به طور موازی با افزایش بار، عملکرد شبکه تغییر میکند، و در مواردی که امکان اضافه کردن ظرفیت در شبکه نیست، باعث کاهش عملکرد شبکه میشود [1]. این سرعت توسعه منعکسکننده قانون مور است. به طور موازی با افزایش بار، عملکرد شبکه تغییر میکند، و در مواردی که امکان اضافه کردن ظرفیت در شبکه نیست، باعث کاهش عملکرد شبکه میشود [2]. به طور همزمان، درخواستهای کاربران، یا به طور دقیقتر درخواستهای برنامه، برای توان عملیاتی[4] و تأخیر افزایش یافته است.
طراحی بهینه ظرفیت شبکههای تلفن سیار، همواره یک چالش برای طراحان شبکه در دهه گذشته بوده است. بعلت آنکه ترافیک شبکههای تلفن همراه به طور تصاعدی در حال افزایش است، با وجود آنکه نرخ رشد شبکههای تلفن همراه به عوامل متنوعی وابسته است، اما ادعا شده است که به صورت میانگین در هر دوسال ترافیک دو برابر شده است[1]. این سرعت توسعه منعکسکننده قانون مور است. به طور موازی با افزایش بار، عملکرد شبکه تغییر میکند، و در مواردی که امکان اضافه کردن ظرفیت در شبکه نیست، باعث کاهش عملکرد شبکه میشود [1]. این سرعت توسعه منعکسکننده قانون مور است. به طور موازی با افزایش بار، عملکرد شبکه تغییر میکند، و در مواردی که امکان اضافه کردن ظرفیت در شبکه نیست، باعث کاهش عملکرد شبکه میشود [2]. به طور همزمان، درخواستهای کاربران، یا به طور دقیقتر درخواستهای برنامه، برای توان عملیاتی[4] و تأخیر افزایش یافته است.
از طرفی، فرآیند اضافه کردن ظرفیت به شبکههای تلفن همراه بسیار طولانی است. معمولاً اپراتورهای تلفن همراه به شش ماه زمان برای اضافه کردن یک لایه 4G یا 5G و دو سال زمان برای ساخت یک ایستگاه پایه جدید نیاز دارند. بطور کلی، برای سرمایه گذاریهای جدید نیاز به توجیه قتصادی بالایی است. از این رو، طراحی بر اساس مدلهای پیشبینی کننده ضروری است. لذا فرآیند تصمیم گیری در مورد افزایش ظرفیت شبکه باید براساس برآورد دقیق عملکرد شبکه در آینده و ارزیابی سناریوهای مختلف رشد ترافیک، عملکرد شبکه و افزایش ظرفیت باشد.
 مشکل پیشبینی تجربه کاربر
مشکل پیشبینی تجربه کاربر
مشکل پیشبینی تجربه کاربر[5] از نظر توان عملیاتی داده در شبکههای تلفن همراه نسل چهارم و پنجم (4G و 5G)، بر اساس تکنیکهای دسترسی چندگانه تقسیم فرکانس متعامد[6] (OFDMA)، میتواند به دو جریان موازی تقسیم شود. طیف فرکانسی اپراتورهای تلفن همراه در هر کانال در باندهای فرکانسی مختلف پخش میشوند. پهنای باند کانال در سیستمهای LTE[7]، برابر 5، 10، 15 یا 20 مگاهرتز است، در حالی که در 5G میتواند در باندهای فرکانس پایین بین 50 تا 100 مگاهرتز و در باندهای فرکانس بالاتر تا 400 مگاهرتز باشد. هر دو سیستم LTE و 5G دارای پنجرههای منابع هستند که در کانالها مستقر شدهاند، بطوریکه طیف دردسترس به بلوکهای منبع (RB) تقسیم میشود. در LTE هر RB دارای اندازه 180 کیلوهرتز است، ولی در 5G اندازه هر RB بسته به مورد استفاده/اعداد[8]، میتوانند مقدار منعطفی بین 180 کیلوهرتز و 1440 کیلوهرتز باشد [3].
در این سیستمها توان عملیاتی دادههای کاربر بوسیله دو مولفه هدایت میشوند. اولین مولفه، تعداد بلوکهای منابع موجود برای هر کاربر است، که به تراکم شبکه (تعداد ایستگاههای مستقر در منطقه مورد نظر)، تراکم کاربر (تعداد کاربرانی که باید در منطقه مورد نظر به آنها خدمات داده شود) و ظرفیت مستقر شده (تعداد کانالهای فرکانس و پهنای باند آنها که توسط ایستگاههای پایه در هر دو فناوری 4G و 5G استفاده میشود) بستگی دارد که بر این اساس میتوان تعداد بلوکهای منابع موجود را بین کاربران به اشتراک گذاشت. دومین مولفه مهم، بهرهوری طیفی سیستم است که بهعنوان توان عملیاتی قابل دستیابی در هر RB اندازهگیری میشود.
تمرکز این مقاله بر مدلسازی بازده طیفی و تحلیل و سنجش آن در یک شبکه فعال با تغییرات واقعی بار شبکه در طول یک بازه زمانی است. نکته مهم و اساسی در تحلیل بار شبکه، درک این موضوع است که الگوهای تغییرات در هر اپراتور تلفن همراه خاص بوده، زیرا به عوامل مختلفی بستگی دارد. بعضی از مهمترین این عوامل شامل؛ داراییهای طیف فرکانسی، تراکم و توپولوژی شبکه، کیفیت طراحی و راهکارهای رادیویی پیاده سازی شده، بلوغ شبکه، توزیع و ترکیب ترافیک کاربران هستند. از اینرو، به جای پیداکردن مدلی که برای همه شبکهها و اپراتورهای مختلف مناسب باشد، هدف را بیشتر تعریف و ساخت چارچوب و متدولوژی تعریف میکنیم که بتواند برای اپراتورهای مختلف، با در نظر گرفتن ویژگیهای متفاوت آنها قابل اعمال و پیاده سازی باشد. در سیستمهای ارتباطی سیار میتوان از قابلیت اندازهگیری عملکرد بسیار پیشرفتهای استفاده کرد. بطوریکه در هر لحظه کانترهای رویدادهای مختلف شبکه را ضبط و معیارهای مختلفی را در دسترس قرار دهند. با استفاده از تکنیکهای یادگیری ماشین، برای تجزیه و تحلیل شاخصها و یادگیری دادههای گذشته، میتوان شرایط و شاخصها را در آینده پیشبینی کرد.
مروری بر کارهای گذشته
در مقالات [4,5] روشهایی بر اساس یادگیری ماشین ارائه شده است که به بررسی مشکلات بهبود سیستم (شکلدهی پرتو[9]، آشکارسازی چندکاربر، طرحهای کدگذاری/کدگشایی، توصیف RF)، آشکارسازی ناهنجاری و پیشبینی ترافیک شبکه، مدیریت منابع، تخصیص طیف و پیشبینی تحویل[10] پرداختهاند. زمانیکه مشکلات طراحی ظرفیت و پیادهسازی آن با روشهای یادگیری عمیق مطرح میشود، اکثر مطالعات منتشر شده درباره مشکلات پیشبینی ترافیک است. برخی از جدیدترین نمونههای مرتبط عبارتند از مقالات [6-10]، که در آن روشهای مختلف با دقت پایینتر یا بالاتر، بسته به توانایی ثبت رویدادهای مختلف، مانند تغییرات فصلی، رویدادهای غیرعادی و یا تغییرات در پیکربندی شبکه، بررسی و آزمایش شدند. با این حال، در فرآیند طراحی ظرفیت، پیشبینی ترافیک را میتوان تنها با اولین مؤلفه تجربه کاربر (که در فصل مقدمه مورد بحث قرار گرفت)، که تعداد بلوکهای منابع موجود برای هر کاربر است، ترسیم کرد. دومین عامل مهم تجربه کاربر، که بهره طیفی است، بر اساس جستجوی نویسندگان، تاکنون مورد توجه قرار نگرفته است. ازطرفی، در شرایطی که تقریباً همه اپراتورهای تلفن همراه با بار ترافیکی فزاینده و سونامی داده دست و پنجه نرم میکنند، سنجش و ارزیابی بهره طیفی و پیشبینی دقیق آن با مدلهای هوش مصنوعی مشکلات بسیار را مرتفع خواهد نمود. ایده جدیدی که با این مقاله معرفی شده است، ارائه و ارزیابی چندین مدل از یادگیری عمیق است بطوری که بتوانند در زمان افزایش شرایط بار شبکه تاثیرات شبکه را تحلیل کنند و با دقت خوبی بهره طیفی را پیشبینی نمایند.
تئوری
سیستمهای ارتباطی سیار که سیستمهای سلولی سیار نیز نامیده میشوند، شبکههایی هستند که با تعداد زیادی ایستگاه ساخته میشوند که هر ایستگاه محدودهای جغرافیایی را پوشش میدهد. محدودهها معمولاً به سه سلول تقسیم میشود. بطور اصولی در ارتباطات راه دور کارایی و ظرفیت کانال رادیویی بر اساس نسبت سیگنال به نویز و تداخل (SINR) بیان میشود. سطح سیگنال نیز بر اساس توان ارتعاش آنتن هر ایستگاه و میزان ارتعاش از دست رفته سیگنال در مسیر رسیدن به تلفن همراه بیان میشود. نویز بصورت نویز حرارتی است که توسط پهنای باند کانال تعریف میشود و تداخل نیز به هر سیگنال ناخواسته دریافتی در کانال گفته میشود. تداخل میتواند داخلی باشد یعنی از یک سیستم مشابه ولی مختص به سایر کاربران باشد یا میتواند خارجی باشد که از سیستمهای دیگر وارد سیستم شما میشوند. در کارایی downlink سیستمهای تلفن همراه نسل چهارم و پنجم، تداخل عمدتاً ناشی از تداخل سیستمهای داخلی است. هر دو سیستم LTE و 5G بر اساس OFDMA هستند، بطوریکه کاربران موجود در یک سلول از یک قسمت از باند فرکانس استفاده نمیکنند، مگر اینکه روشهای چندکاربره، چندگانه ورودی چندگانه خروجی (MIMO) پیاده سازی شده باشد. تاثیر تداخل MIMO بر کارایی سیستم بسیار محدود است. بر این اساس، منبع اصلی تداخل، سیگنال دریافتی است که به کاربران دیگر اختصاص داده شده است، که در آن جزء غالب، تداخل درون سلولی است که از سلولهای همسایه تحمیل میشوند.
کیفیت کانال رادیویی در سلولهای سیستمهای تلفن همراه، از نزدیکترین نقطه به آنتن تا لبه انتهایی سلول، بسیار متفاوت است و در زمانهای مختلف بصورت پویایی در حال تغییر هستند، بنابراین زمانبندیهای LTE و 5G NR باید پارامترهای اتصال را تنظیم کنند تا بهترین تجربه کاربری ممکن را ایجاد کنند. به این فرآیند انطباق پیوند[11] میگویند. انطباق پیوند بر اساس فاصله زمانی انتقال (TTI)[12] که براساس دستهبندی 1 میلی ثانیه است، مقدار دادههای طول TTI، مدولاسیون و MIMO بگونهای انتخاب میشوند که مقدار دادههای ارسالی و احتمال رمزگشایی موفقیت آمیز دادهها حداکثر باشند.
این فرآیند براساس گزارشهایی است که توسط تجهیزات کاربر (UE)، به ایستگاه ارسال میشوند (شکل 1). گزارشات شامل اطلاعاتی در مورد کیفیت کانال است که توسط استاندارد 3GPP به عنوان گزارش اطلاعات وضعیت کانال (CSI)[13] تعریف شده است. این گزارشات دارای سه مولفه اصلی: شاخص کیفیت کانال (CQI)[14]، شاخص ماتریس پیش کدگذاری PMI[15] و نشانگر رتبه RI[16] است.
از منظر تطبیق پیوند، CQI مهمترین مولفه است، زیرا به طور ضمنی نرخ داده انتقال downlink را نشان میدهد. دامنه CQI مقادیر گسسته بین 0 تا 15 است، که شاخص 15، بهترین کیفیت کانال و شاخص 0، نشاندهنده ضعیف ترین کیفیت کانال است [10]. براساس استاندارد 3GPP، نگاشت CQI برای مدولاسیونهای مختلف، در جدول 1 آورده شده است (نرخهای کدگذار ارائه شده در جدول با ضریب 1024 ضرب میشوند).
جدول 1: نگاشت CQI برای مدلاسیونهای مختلف [10]
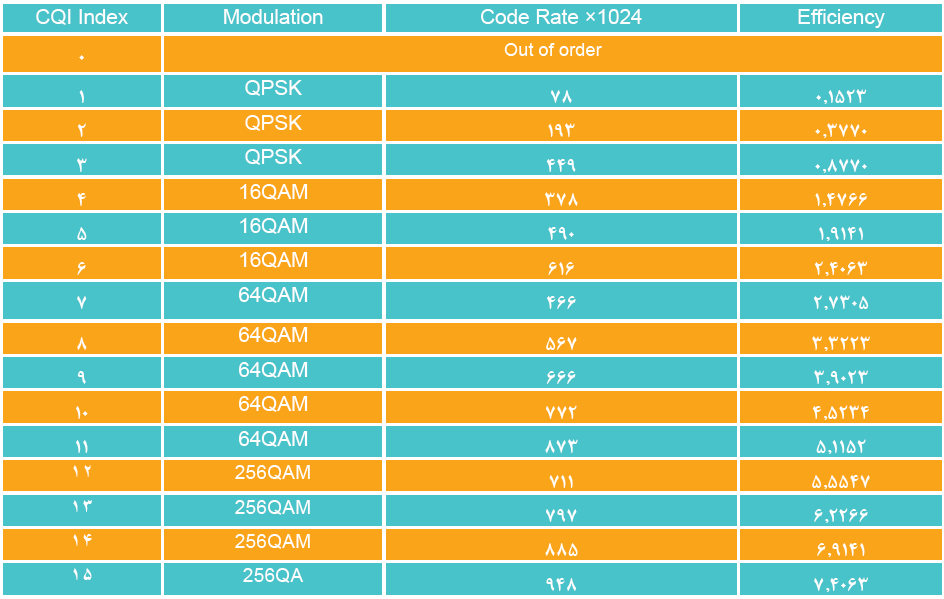
شاخص رتبه[17] یکی دیگر از عوامل مهم برای پیشبینی بازده طیفی است، زیرا بسته به عملکرد MIMO، جریانهای تقریباً موازی در سناریوهای چندگانه فضایی وجود خواهند داشت. برخی از اولین نتایج تجزیه و تحلیل عملکرد در این حوزه به بازده طیفی بهتر در سیستمهای 5G در مقایسه با 4G اشاره میکنند که عمدتاً با استفاده از شاخص رتبه بالاتر و عملکرد MIMO بهتر از نظر مالتی پلکس فضایی به دست میآید. محتملترین دلیل آن، افزایش تعداد عناصر آنتن برای سیستمهای رادیویی 5G است.
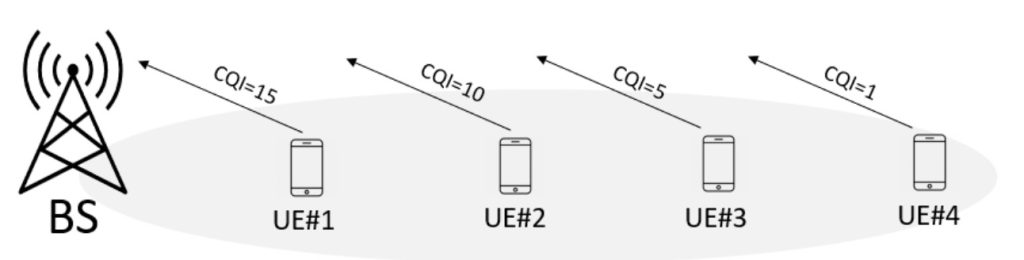
شکل 1: در یک سلول CQI گزارشات
تعریف مشکل و روش تحقیق
بر اساس مطالب گفته شده، برای حل مشکل پیشبینی بازده طیفی یک پیشبینی خوب از CQI و شاخص رتبه میتواند اثرگذاری بسیاری داشته باشد. در کار قبلی [11]، نویسندگان همبستگی بین استفاده از CQI و MIMO را بررسی کردند، در حالی که تمرکز این مقاله مدلسازی CQI است. بیشتر تحقیقات در این زمینه بر روی شبیهسازهای شبکه و مدلهای عملکردی متمرکز است که عملکرد آنها کلی است ، با برخی فرضیات در مدلسازی که میتواند دقت مدل را محدود کند. علاوه بر این، آنها معمولاً بر طراحی سیستم و الگوریتم متمرکز هستند و به ندرت با مشکلات طراحی شبکه سروکار دارند [12-15]. دلیل این امر این است که دانشگاهیان و محققان به ندرت درگیر صنعت هستند و به دادههای شبکههای واقعی دسترسی کمتری دارند. مقالات و مطالعات تحقیقاتی بسیار کمی در مورد CQI که رویکردهای نظری و تجربی را با هم ترکیب میکنند، وجود دارد. از طرفی، در فرآیند ارزیابی شبکه سیستم جهانی ارتباطات سیار GSM[18] از 3G گرفته تا LTE و اخیراً تا سیستمهای 5G-NR، شبکهبندی مکانهای شبکه مورد استفاده برای ایستگاهها تغییر چندانی نکردهاند. همچنین برخی از ویژگیهای اصلی طراحی شبکه، مانند ارتفاع آنتن و آزیموت نیز همچنان تغییر چندانی ندارند. به همین دلیل، بسیاری از مدلسازیهای کارایی شبکه را میتوان بر اساس دادههای گذشته و شناخت الگوهای ترافیکی و تاثیرات[19] شبکه انجام داد. رویکرد نویسندگان به مسئله پیشبینی کارایی شبکه از دادههای تلفن همراه تجاری، کار با مجموعه دادههای عظیم، ساختن الگوریتمها و مدلهایی است که بتوان آن را در هر شبکه سلولی موبایلی با ویژگیها و تاثیرات مختلف اعمال کرد.
جمع آوری دادهها در شبکه تلفن همراه بوسیله سیستمهای مدیریت عملکرد [20]PM انجام میشود. استاندارد 3GPP نحوه جمع آوری شمارندهها را مشخص میکند. هر وندور شبکه دسترسی رادیویی RAN[21] دارای سطحی از اختیار برای ایجاد فرآیند جمعآوری دادهها پیرامون رویدادهای مختلف شبکه است. این درحالی است که تفاوت زیادی بین راه حلهای RAN در طراحی سیستمهای PM وجود ندارد و اصولا شاخصهای اصلی مشابه هستند. شاخص اصلی مورد استفاده در این مقاله گزارشات شاخص CQI است که به عنوان تابع توزیع تجمعی CDF[22] در دورههای مختلف شامل ساعت و روز (24 ساعت)، در هر سلول تجزیه و تحلیل میشود. ارزیابی فرآیند گزارش CQI با تغییرات در بار شبکه، که در واقع مصرف RB در خود سلول سرویسدهی و سلولهای اطراف است، اندازهگیری و تجزیه و تحلیل میشود.
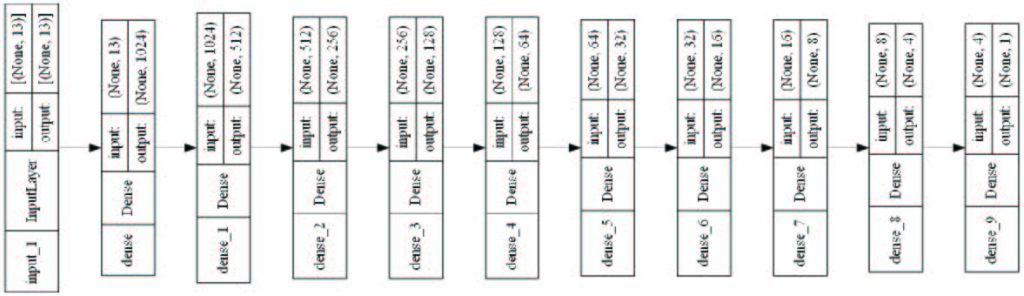
شکل 2: مدل پیشنهادی شبکه یادگیری عمیق
انتخاب ویژگیهای شبکه
هدف این مقاله طراحی مدلی بر اساس شبکههای یادگیری عمیق است که بتواند شاخص CQI را در شرایط بار شبکه پیشبینی کند. ایده اصلی تقسیم بندی سلولها بر اساس عوامل مهم و محرکهای اصلی عملکرد سیستم است. از این رو از پنج ویژگی زیر که میتواند دقت پیشبینی مدل را بهبود بخشد استفاده شده است [14].
- باند فرکانسی
- بلوک منبع فیزیکی PRB استفاده شده در سلولهای اطراف
- تعداد سلولهای همسایه اطراف در شعاع 2.5 کیلومتری
- ظرفیت ترابری دانلود و آپلود
- استفاده از مرتبه بالاتر مدولاسیون
اصولا تقسیمبندی بر اساس باند فرکانس انجام میشود، زیرا انتشار رادیویی در فرکانسهای مختلف متفاوت است. از طرفی همانطور که اشاره شد، تداخل بین سلولی، فاکتور اصلی کارایی سیستم است. از این رو، کارایی سلولهایی که در فرکانسهای پایینتر کار میکنند، بیشتر تحت تأثیر تداخل در سناریوهای شبکه با بار تراکمی زیاد قرار میگیرد، چون انتشار رادیویی و احتمال بیشتر تداخل سیگنال از سلول همسایه با سیگنال سلول سرویس دهنده بیشتر است.
یکی دیگر از شاخصها، تعداد سلولهای همسایه در یک شعاع مشخص است. این شاخص تراکم شبکه را نشان میدهد. ایده، که قبلا در [16،17] بررسی شد، این است که هر چه یک شبکه متراکم تر باشد، حساس تر به تداخل خواهد بود. میانگین مصرف PRB (تعیین شده براساس سلولهای اطراف و میانگین) و کل مصرف PRB (تجمیع شده براساس سلولهای اطراف، کپسوله کردن تعداد همسایگان در امتیاز کلی) هر دو مورد بررسی قرار گرفتند. سلولهای همسایه به عنوان سلولهایی در یک شعاع انتخاب شده مشخص، تعریف شدند. شعاع 2.5 کیلومتر، 5 کیلومتر و 10 کیلومتر مقایسه شد. بهترین عملکرد با استفاده از تعریف شعاع 5 کیلومتری سلولهای اطراف بود، اگرچه عملکرد با استفاده از 2.5 کیلومتر مشابه بود. شعاع 10 کیلومتری منجر به عملکرد بسیار بدتر از 5 کیلومتر یا 2.5 کیلومتر شد.
در نهایت، بار در سلولهای همسایه، که به عنوان میانگین مصرف PRB اندازهگیری میشود، برای بخشبندی بخشهایی از شبکه با ترافیک بالاتر تعریف میشود. استفاده از مدولاسیون مرتبه بالاتر به عنوان شاخصی انتخاب شده که توزیع کاربران در فضا و سلولها را بر اساس شرایط متوسط رادیویی تقسیم میکنند که به عنوان درصد استفاده از 64QAM و 256QAM تعریف میشود. سلولهایی که کاربران نزدیکتر به آنتن هستند، در شرایط رادیویی خوب هستند و مقادیر بالاتری خواهند داشت. آخرین شاخص، فاکتور داده سنگین است، که با ایده بخش بندی سلولها در آن بر اساس نوع ترافیک است. در برخی از موارد، مانند سرویسهای پخش ویدئو یا دانلود سنگین FTP، از منابع شبکه LTE/5G-NR به میزان بسیار بیشتری نسبت به سایر موارد استفاده میشود. با شمارندههای موجود در سیستمهای PM، گرفتن حجم ترافیک کار آسانی نیست. نویسندگان سعی کرده اند این را با نسبت بار داده در سلول و مصرف PRB دریافت کنند. با این حال، همبستگی زیادی بین هر دو عامل دادههای سنگین و ویژگیهای مدولاسیون مرتبه بالاتر با بازده طیفی وجود دارد.
داده و مدل شبکه و اعتبارسنجی
در این مقاله، دادههای مورد نیاز از سیستم فراز برای وندور Huawei و برای تکنولوژی 4G در مدت زمان سه ماه تابستان ازتاریخ 1 ژوئن تا 1 سپتامبر جمعآوری شده است. باند فرکانسی دادههابرای تمام رکوردها 15 و 20 بوده و چون باندهای فرکانسی مشابه هنگام نرمالسازی دادهها همانند نویز عمل کرده، از فرایند آموزش مدل حذف شده است.
ستون دادههای استفاده شده به شرح زیر میباشد:
- منابع فیزیکی دانلود و آپلود
- فاکتور دادههای سنگین در این سیستم payload ساعتی دانلود و آپلود در نظر گرفته شده
- در این مطالعه سلولهای همسایه تنها اطلاعات 6 سلول در شهر تهران بوده
- برای مقدار مدولاسیون از میانگین آنها استفاده شده
- بازده طیفی
مدل شبکه عمیق پیشنهادی در شکل 2 آورده شده است. همانطور که قبلاً اشاره شد، دادههای مورد نیاز برای هر سلول با استفاده از سیستمهای PM جمع آوری و تهیه شده است. دادههای این تحقیق از دادههای اپراتور همراه اول ایران است که شامل شبکه LTE است. دادههای 6 ایستگاه که در باندهای فرکانسی مختلف LTE (1800 و 2100 مگاهرتز) کار میکنند. البته امکان زیاد کردن ایستگاههای دیگر نیز وجود دارد که در باندهای پایین تر یعنی 900 مگاهرتز کار میکنند ولی بدلیل محدودیت سخت افزاری فعلا به این تعداد ایستگاه و داده بسنده شده است. دادههای ورودی به دو صورت کلاسترینگ زمانی یک ساعته و کلاسترینگ زمانی یک روزه (24 ساعته) تنظیم و به دو مدل جداگانه بعنوان ورودی داده شده است.
دادهها در یک دوره سه ماهه با بازه زمانی یک ساعته، با بیش از 2000 رکورد در هر سلول جمعآوری شد. در پیش پردازش اولیه، مصرف PRB در سلولهای اطراف، تعداد سلولهای اطراف، میانگین مصرف PRB در سلولهای اطراف، ظرفیت ترابری دانلود و آپلود و مدولاسیون مرتبه بالاتر از دادههای خام در نظر گرفته شده است. مدل پیشنهادی یادگیری عمیق برای پیشبینی میانگین CQI با استفاده از این ورودیها آموزش داده شده است. در طول آزمایش، عملکرد مدل بر روی دادههای دیده نشده ارزیابی میشود. 80 درصد از دادهها به عنوان داده آموزشی و 20 درصد بقیه به عنوان داده تست و ارزیابی انتخاب شدهاند. شبکه عصبی با استفاده از کتابخانه Keras [22،23]، معماری پیشخور، با تابع فعالسازی Relu و بهینهساز Adam پیادهسازی شد.
دو مدل با ورودیهای مختلف برای پیشبینی CQI طراحی شده است. مدل اول با 9 لایه dense با ورودی ساعتی و مدل دوم با 4 لایه dense طراحی شده است.
با توجه به اینکه مسئله از نوع رگرسیون میباشد، میانگین درصد مطلق خطا MAE[23] به عنوان معیار عملکرد بهکار گرفته شده است. MAE با توجه به معادله 1، محاسبه میشود.
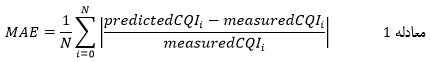
نتایج مدل پیشنهادی و اعتبارسنجی
با توجه به کم بودن تعداد سلولهای ایستگاهها و برای جلوگیری از حالت بیش برازش[24] در مدل و یادگیری بیشتر، از اعتبارسنجی متقابل با پنج لایه و زیرمجموعه استفاده شده است.
اعتبارسنجی متقابل[25]، یک روش ارزیابی مدل است که تعیین مینماید نتایج یک تحلیل آماری بر روی یک مجموعه داده تا چه اندازه قابل تعمیم و مستقل از دادههای آموزشی است. این روش بهطور ویژه در کاربردهای پیشبینی مورد استفاده قرار میگیرد تا مشخص شود مدل موردنظر تا چه اندازه در عمل مفید خواهد بود. بهطور کلی یک دور از اعتبارسنجی متقابل شامل افراز دادهها به دو زیرمجموعه مکمل، انجام تحلیل بر روی یکی از آن زیرمجموعهها (دادههای آموزشی) و اعتبارسنجی تحلیل با استفاده از دادههای مجموعه دیگر است (دادههای اعتبارسنجی یا آزمایش). برای کاهش پراکندگی، عمل اعتبارسنجی چندین بار با افرازهای مختلف انجام و از نتایج اعتبارسنجیها میانگین گرفته میشود. در اعتبارسنجی متقابل K لایه، دادهها به K زیرمجموعه افراز میشوند. از این K زیرمجموعه، هر بار یکی برای اعتبارسنجی و K-1 تای دیگر برای آموزش به کار میروند. این روال K بار تکرار میشود و همه دادهها دقیقاً یک بار برای آموزش و یک بار برای اعتبارسنجی به کار میروند. درنهایت میانگین نتیجه این K بار اعتبارسنجی بهعنوان یک تخمین نهایی برگزیده میشود[24]. در این مطالعه از k=5 استفاده شده است.
در ادامه در شکلهای 3، نمودارهای دادههای پیشبینی و دادههای ارزیابی بر اساس MAE در K-foldهای مختلف آورده شده است. همانطور که از نمودارها در K-foldهای مختلف مشخص است، فارغ از نوع داده ورودی برای آموزش و یا ارزیابی، مدل پیشنهادی، قادر به همگرا کردن دادهها هست.
در شکلهای 4، نمودارهای پراکندگی در K-foldهای مختلف آورده شده است. همانطور که از نمودارها در K-foldهای مختلف مشخص است، فارغ از نوع داده ورودی برای آموزش و یا برای ارزیابی، مدل پیشنهادی قابلیت پیشبینی پراکندگی دادهها در سلولها مختلف را دارد.
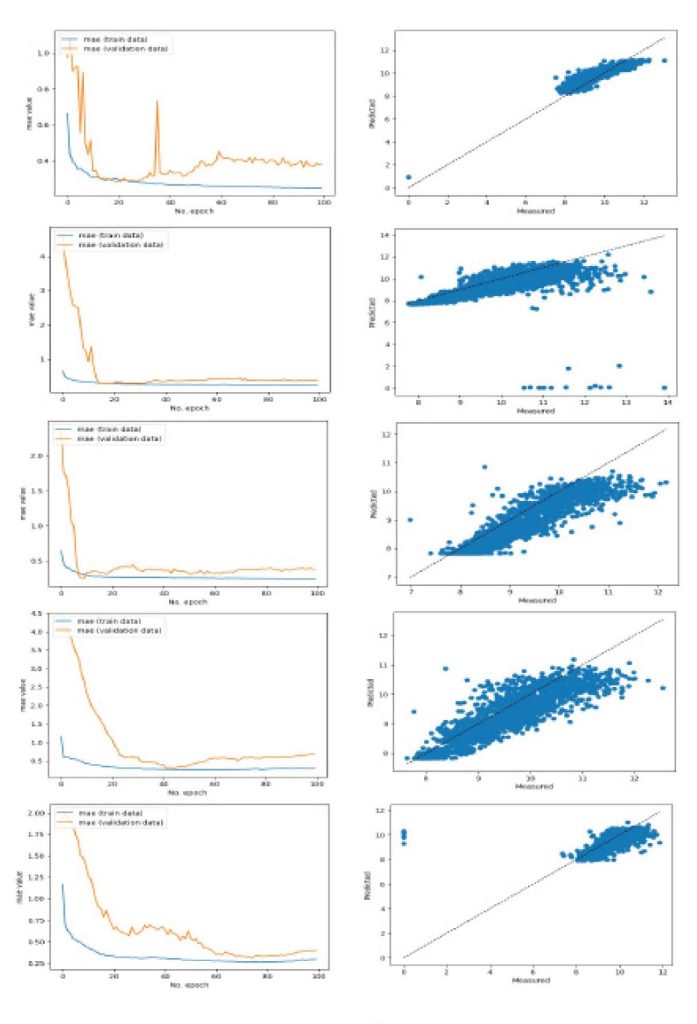
شکل 3: مقایسه نمودار داده آموزشی و داده اعتبارسنجی و نمودارهای پراکندگی در K-foldهای مختلف با زمان یکساعته
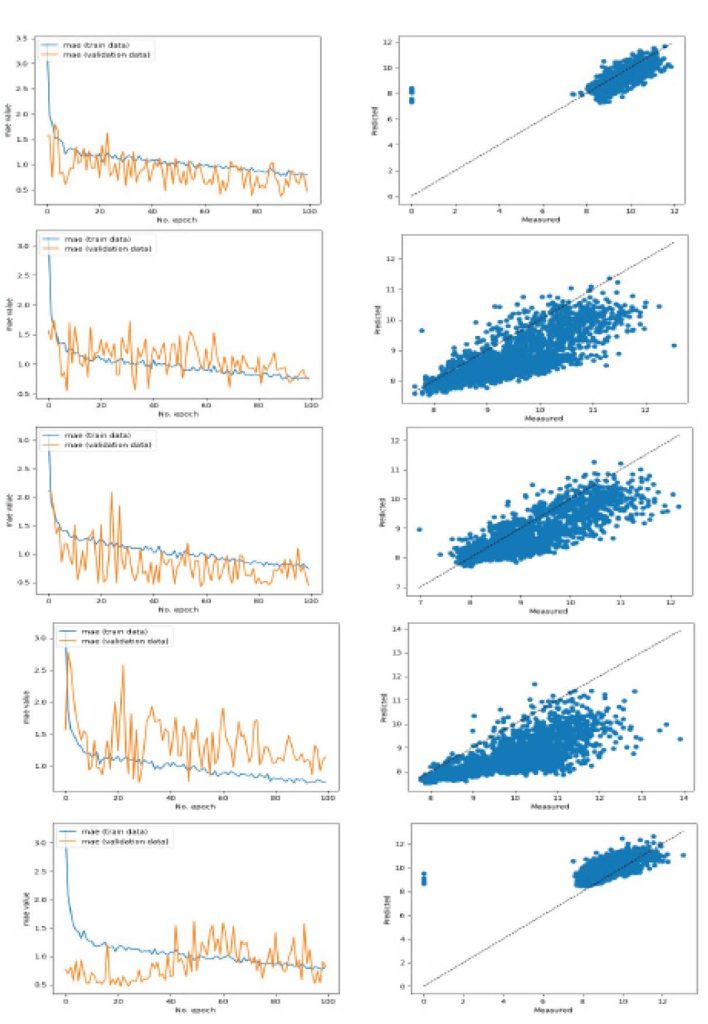
شکل 4: نمودارهای آموزش داده و ارزیابی در کنار نمودار پراکندگی در K-foldهای مختلف برای مدل داده 24ساعته
نتیجهگیری
اصل تحقیق انجام شده در این مقاله استفاده از یادگیری عمیق برای مشکلات طراحی شبکه، برنامهریزی ظرفیت و بهخصوص، مدلسازی ارزیابی بازده طیفی در شرایط بار شبکه رو به رشد است. نتایج دو مدل در بازه زمانی یک ساعت و 24 ساعته در این مقاله ارائه شده که شامل اطلاعات 6 سلول است و قابلیت بسط دادن به تعداد بیشتر سلول را در آینده خواهد داشت. از طرفی، چند شاخص کارایی شبکه با این ایده برای بالاتر بردن دقت مدل عصبی عمیق تحلیل و معرفی شد. همبستگی قوی بین CQI و مصرف PRB، payload و مدولاسیون مشاهده میشود و همچنین همبستگی قویتری با مصرف PRB زمانی که سلولهای اطراف اضافه میشوند، نیز مشاهده شد. ولی با این حال، نویسندگان تصمیم گرفتند تا میانگین مصرف و تعداد سلولهای اطراف در شعاع 2.5 کیلومتر را به عنوان ویژگیهای جداگانه معرفی کنند.
منابع
[1] Ericsson Mobility Report, November 2021. Available online: https://www.ericsson.com/en/reports-and-papers/mobility-report (accessed on 13 January 2022).
[2] Tomi´c, I.; Davidovi´c, M.; Bjekovi´c, S. On the downlink capacity of LTE cell. In Proceedings of the 23rd Telecommunications Forum TELFOR, Belgrade, Serbia, 24–25 November 2015; pp. 181–185. [CrossRef]
[3] Dahlman, E.; Parkvall, S.; Skold, J. Overall Transmission Structure. In 5G NR: The Next Generation Wireless Access Technology; Academic Press: London, UK; San Diego, CA, USA, 2020; pp. 103–131.
[4] Santos, G.L.; Endo, P.T.; Sadok, D.; Kelner, J. When 5G Meets Deep Learning: A Systematic Review. Algorithms 2020, 13, 208. [CrossRef]
[5] Zhang, C.; Patras, P.; Haddadi, H. Deep learning in mobile and wireless networking: A survey. IEEE Commun. Surv. Tutor 2019, 21, 2224–2287. [CrossRef]
[6] Gijón, C.; Toril, M.; Luna-Ramírez, S.; Marí-Altozano, M.L.; Ruiz-Avilés, J.M. Long-Term Data Traffic Forecasting for Network Dimensioning in LTE with Short Time Series. Electronics 2021, 10, 1151. [CrossRef]
[7] Bastos, J. Forecasting the capacity of mobile networks. Telecommun. Syst. 2019, 72, 231–242. [CrossRef]
[8] Li, R.; Zhao, Z.; Zheng, J.; Mei, C.; Cai, Y.; Zhang, H. The learning and prediction of application-level traffic data in cellular networks. IEEE Trans. Wirel. Commun. 2017, 16, 3899–3912.
[9] Hua, Y.; Zhao, Z.; Liu, Z.; Chen, X.; Li, R.; Zhang, H. Traffic prediction based on random connectivity in deep learning with long short-term memory. In Proceedings of the 2018 IEEE 88th Vehicular Technology Conference (VTC-Fall), Chicago, IL, USA, 27–30 August 2018; pp. 1–6.
[10] Evolved Universal Terrestrial Radio Access (E-UTRA); Physical Layer Procedures, 3GPP TS 36.213 15.7.0. Available online: https://www.etsi.org/deliver/etsi_ts/136200_136299/136213/15.07.00_60/ts_136213v150700p.pdf (accessed on 31 January 2022).
[11] Tomi´c, I.; Luki´c, Ð.; Davidovi´c, M.; Draji´c, D.; Ivaniš, P. Statistical analysis of CQI reporting and MIMO utilization for downlink scheduling in live LTE mobile network. Telfor J. 2020, 12, 8–12. [CrossRef]
[12] Kumar, V.; Mehta, N.B. Modeling and Analysis of Differential CQI Feedback in 4G/5G OFDM Cellular Systems. IEEE Trans. Wirel. Commun. 2019, 18, 2361–2373. [CrossRef]
[13] Yin, H.; Guo, X.; Liu, P.; Hei, X.; Gao, Y. Predicting Channel Quality Indicators for 5G Downlink Scheduling in a Deep Learning Approach. Available online: https://arxiv.org/pdf/2008.01000.pdf (accessed on 31 January 2022).
[14] Rassa, E.H.R.; Ramli, H.A.M.; Azman, A.W. Analysis on the impact of outdated channel quality information (CQI) correction techniques on real-time quality of service (QoS). In Proceedings of the IEEE Student Conference on Research and Development (SCOReD), Bangi, Malaysia, 26–28 November 2018.
[15] Torres J., G.; Bustamante, R. Analysis of the effects of CQI Feedback for LTE Networks on ns-3. IEEE Latin Am. Trans. 2015, 13,3538–3543. [CrossRef]
[16] Tomi´c, I.; Davidovi´c, M.; Draji´c, D.; Ivaniš, P. On the impact of network load on CQI reporting and Link Adaptation in LTE systems. In Proceedings of the IcEtran, Staniši´ci, Bosnia and Herzegovina, 8–10 September 2021; pp. 612–624.
[17] Djuri´c, K.; Tomi´c, I.; Neskovi´c, A. On the impact of Network density on correlation between Network load and Link adaptation in MIMO-OFDM based Mobile Broadband Networks. In Proceedings of the 29th Telecommunications Forum TELFOR 2021, Belgrade, Serbia, 23–24 November 2021; 2021. [CrossRef]
[18] Weisberg, S. Applied Linear Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013.
[19] Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Duchesnay, E. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830.
[20] Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [CrossRef]
[21] XGBoost Python Package. Available online: https://xgboost.readthedocs.io/en/stable/python/index.html, (accessed on 13 January 2022).
[22] Fine, T. Feedforward Neural Network Methodology; Springer: New York, NY, USA, 1999.
[23] Chollet, F. Keras. Available online: https://github.com/fchollet/keras. (accessed on 13 January 2022).
[24] Live:https://machinelearningmastery.com/k-fold-cross-validation
پینوشت
[1] Download and Upload Payload
[2] High Modulation
[3] Channel Quality Indicator
[4] Throughput
[5] user experience
[6] Orthogonal Frequency Division Multiple Access (OFDMA)
[7] Long Term Evolution
[8] use case/numerology
[9] beamforming
[10] handover
[11] Link Adaptation
[12] Time to Transmit Interval
[13] Channel State Information report
[14] Channel Quality Indicator
[15] Precoding Matrix Index
[16] Rank Indicator
[17] Rank Indicator
[18] Global System for Mobile
[19] signature
[20] Performance Management
[21] Radio Access Network
[22] Cumulative Distribution Function
[23] Mean Absolute Error
[24] Overfitting
[25] Validation




