


پشته فناوری کلانداده
کلانداده؛ یک اصطلاح برای مجموعه دادههای خیلی بزرگ است که از نظر ساختار، پیچیدگی و منابع تولیـد، بسیار متنوع بوده و ذخیره و آنالیز آنها کار پیچیدهای است. حجم بسیار بالای داده، موجب کاهش سرعت تولید، کاهش تنوع فرمتهای داده و همچنین محدودیت در توانایی تجزیهوتحلیلهای کارآمد با استفاده از پایگاههای داده رابطهای میشود که پردازش کارآمد این دادهها، مستلزم بهکارگیری فناوریهای اطلاعاتی نوینی است. کلانداده؛ چالش مهمی است که برای اطمینان از انجام موفق پردازشها و آنالیزهای مورد نیاز، به زیرساختی قوی احتیاج دارد. معماریهای ارائهشده برای دادههای حجیم به شرکتهای مخابراتی امکان میدهد که انواع جدیدی از دادهها را ذخیره کنند، آنها را برای مدت طولانیتری حفظ و مجموعه دادههای متنوع را با یکدیگر ادغام کرده تا بینش جدید و ارزشمندی کسب کنند. معماری مرجع ارائهشده در این گزارش، ترکیبی است از رویکردهایی که در اغلب شرکتهای مخابراتی مورد استفاده قرار میگیرد.
کلیدواژهها : پشته فناوری، دادههای حجیم، معماری، هادوپ، صنعت مخابرات
 معماری دادههای حجیم
معماری دادههای حجیم
![]() دادههای حجیم ممکن است ساختیافته، غیرساختیافته یا نیمهساختیافته باشند. دادههای ساختیافته فقط 20 درصد از دادههای حجیم ذخیرهشده در پایگاه دادهها را تشکیل میدهند، درحالی که 80 درصد از دادهها، غیرساختیافته هستند. بهطور مثال، دادههای جمعآوریشده از اینترنت، شامل دادههای تولیدشده توسط کاربران، دادههای موجود در شبکههای اجتماعی و دادههای جمعآوریشده از طریق شبکههای حسگر و اینترنت اشیاء، پویا و غیرساختیافته هستند.
دادههای حجیم ممکن است ساختیافته، غیرساختیافته یا نیمهساختیافته باشند. دادههای ساختیافته فقط 20 درصد از دادههای حجیم ذخیرهشده در پایگاه دادهها را تشکیل میدهند، درحالی که 80 درصد از دادهها، غیرساختیافته هستند. بهطور مثال، دادههای جمعآوریشده از اینترنت، شامل دادههای تولیدشده توسط کاربران، دادههای موجود در شبکههای اجتماعی و دادههای جمعآوریشده از طریق شبکههای حسگر و اینترنت اشیاء، پویا و غیرساختیافته هستند.
معماری پایگاه دادههای رابطهای و تحلیلی سابق، پاسخگوی ذخیرهسازی و تحلیلهای لازم برای دادههای حجیم نیست. دادههای حجیم باید بدون درنگ و کمترین وقفهای نسبت به پایگاه دادههای سابق تحلیل شوند. ذخیرهسازی و پردازش این حجم از دادهها مستلزم معماریهای موازی درون حافظهای و مقیاسپذیری است.
معماری مرجع
استخراج دانش از دادهای حجیم شامل چهار فرآیند اصلی «تولید و انتقال»، «ذخیرهسازی»، «تحلیل» و «بصریسازی» است که برنامهریزی جهت توسعه آنها نیازمند تبیین و نمایش موضوعات مطرح در این حوزه در قالب یک معماری مرجع است. معماری مرجع در هر حوزه، مرجع اطلاعاتی در رابطه با موضوعات مطرح در آن حوزه بهصورت یک شکل واحد است که با استفاده از آن میتوان تعاریف واحد را تبیین کرد و بهراحتی و در یک نگاه به تمام مفاهیم و موضوعات مطرح در آن حوزه پیبرد. معماری مرجع موضوعی، بهعنوان یک پایه و اساس برای پیادهسازی معماریهای راهکارهای عملی استفاده میشود و همچنین میتواند برای مقایسه و جهتدهی سریع به دیدگاهها و راهکارهای مختلف مورد استفاده قرار گیرد. در این بخش، الزامات مطرح برای توسعه یک معماری مطلوب کلاندادهای آورده شده است.
در سیستم معمول پردازش دادههای حجیم، معماری پردازش دادهها شامل لایههای جمعآوری و پیشپردازش، ذخیرهسازی، تجزیهوتحلیل، واکاوی و کاربرد ارزش است.
لایههای داده و مشکل تعریف کلانداده
مشکل واقعی در تعریف کلانداده در لایه منابع داده شروع میشود که بر اساس آن، منابع دادهای در حجمها، نرخ تولید مختلف و تنوع، با هم رقابت میکنند تا در مجموعه نهایی دادهای که در کلانداده مورد تحلیل قرار میگیرند، خود را جای دهند. لایه منبع داده، متشکل از دادههای شرکتها، صنعت، اینترنت و اینترنت اشیاء است (شکل 1).
در لایه جمعآوری اطلاعات، روی دادههای جمعآوریشده از طریق لایه منبع داده، پیشپردازشهایی انجام میشود. این پیشپردازشها شامل پاکسازی دادهها و پردازش دادههای ناهمگن است.
در لایه ذخیرهسازی، دادههای ساختیافته، غیرساختیافته و نیمهساختیافته، ذخیره و مدیریت میشوند. در لایه پردازش داده نیز، دادهها تجزیهوتحلیل و واکاوی میشوند تا کاربران بتوانند سرویسهای رایج مخابراتی را تجزیهوتحلیل کنند.
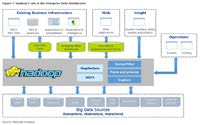
شکل 1: نقش هادوپ در معماری دادههای سازمانی [1]
فناوریهای کلیدی
فناوریهای مورد استفاده در لایههای مختلف معماری دادههای حجیم، نسل جدیدی از فناوریها و معماریها هستند که امکان دریافت و ذخیرهسازی، کاوش و/یا تجزیهوتحلیل خیلی سریع را برای استخراج ارزش از حجم بالایی از دادههای بسیار متنوع فراهم میآورند.
بسیاری از فناوریها در اکوسیستم دادههای بزرگ، منشأ منبعباز دارند. محبوبیت و دوام این ابزارهای منبعباز، فروشندگان را بر آن داشته تا نسخههای خود را از ابزارها راهاندازی کنند. چارچوب هادوپ همراه با مؤلفههای نرمافزاری اضافی مانند R و طیفی از ابزارهای NoSQL مانند Cassandra و Apache Hbase هسته اصلی چارچوب دادههای بزرگ است.
هادوپ
هادوپ یک چارچوب متنباز برای ذخیره، پردازش و تحلیل حجم عظیمی از دادههای توزیعشده است. این چارچوب، قابلیت ذخیرهسازی و محاسبات توزیعشده روی خوشههای سختافزاری را فراهم میکند. معماری هادوپ، یک معماری Master/Salve توزیعشده است که از فایل سیستم توزیعشده با نام Hadoop Distributed File System) HDFS) برای ذخیرهسازی و مدل برنامهنویسی MapReduce برای پردازش توزیعشده تشکیل میشود. بهطورکلی، هادوپ یک سکو یا مجموعهای از نرمافزارها و کتابخانههایی است که سازوکار پردازش حجم عظیمی از دادههای توزیعشده را فراهم میکند. درواقع، حجم زیادی از دادهها را بر روی ماشینهای مختلف، پردازش و مدیریت میکند.
هادوپ از اجزای اصلی زیر تشکیل شده است:
- بخش ذخیرهسازی با عنوان سیستم فایل توزیعشده Hadoop (HDFS) که وظیفه تقسیم، ذخیره و بازیابی فایلهای حجیم روی یک کلاسترHadoop را برعهده دارد.
- بخش پردازش به نام بخش نگاشت و تجمیع (MapReduce)؛ مسئول تحلیل و پردازش دادههای توزیعشده است.
- بسته عمومی هادوپ (Hadoop common) که کتابخانهها و برنامههای کاربردی مورد استفاده توسط سایر ماژولهای هادوپ است.
جزئیات تماس[1](CDR): رکورد CDR شامل اطلاعات تماسها ازجمله شماره مبدأ، شماره مقصد، تاریخ و زمان شروع تماس، زمان برقرار شدن تماس و زمان پایان است. ماژول Apache Flume یکی از مؤلفههای اکوسیستم هادوپ برای جمعآوری دادههای جریانی غیرساختیافته همراه با قابلیت اطمینان است. برای شناسایی الگوهای نامتعارف، این ماژول میتواند میلیونها رکورد CDR را در هر ثانیه به هادوپ وارد کند، تا ماژول Apache Storm آنها را با سرعت بالا و بدون وقفه پردازش کند. تجزیهوتحلیل مستمر رکوردهای CDR میتواند برای بهبود مداوم کیفیت تماس و کمک به فعالیتهای بازاریابی مورد استفاده قرار گیرد.
کشف تقلب و تخلف[2]: توزیع MapReduce به ساخت مدلهایی کمک میکند که میتوانند برای شناسایی تماسهای تلفنی غیرعادی که نشاندهنده سرقت یا هک هستند، مورد استفاده قرار گیرند.
مدل محاسباتی نگاشتکاهش (MapReduce)
مدل نگاشتکاهش (شکل 2) یک مدل برنامهنویسی توزیعشده است که امکان مقیاسپذیری گسترده را روی صدها یا هزاران سرور موجود در خوشه هادوپ فراهم میآورد. این مدل، به توسعهدهندگان امکان میدهد که برنامههای خود را برای پردازش حجم زیادی از دادههای غیرساختیافته بهشکل موازی و روی یک خوشه پردازنده بنویسند. مدل برنامهنویسی نگاشتکاهش، اجازه اجرای پردازش توزیعشده و موازی روی مجموعه بزرگی از دادهها را میدهد. در مدل نگاشتکاهش، پردازش بین چندین گره، تقسیم شده و هر گره بهطور همزمان، بخشی از کار را انجام میدهد.
ریزش مشتریان: نگاشتکاهش به تجزیهوتحلیل کارآمد تمام مجموعه دادهها کمک میکند. بهطور مثال، میتواند در توسعه مدلها برای پیشبینی مشتریان رویگردان و غیررویگردان استفاده شود.
انبار داده HIVE
Hive مخفف (Hive Query Language) HiveQL یا HQL برای ارائه پرسوجو در بالای هادوپ ساخته شده است که تجزیهوتحلیل دادههای عظیم ذخیرهشده در فایل سیستم توزیعشده هادوپ را پشتیبانی میکند. این پایگاه داده، یک زبان
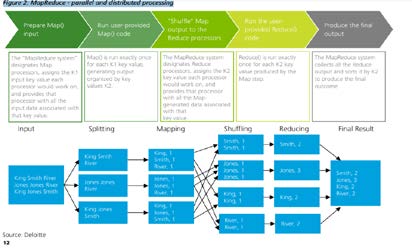
شکل 2: مدل محاسباتی توزیعشده نگاشت کاهش [1]
پرسوجو مشابه SQL به نام HiveQL ارائه کرده است. درواقع، Hiveیک انبار داده در اکوسیستم هادوپ است که مسئولیت خواندن، نوشتن و مدیریت مجموعه دادههای بزرگ را در یک محیط توزیعشده و با استفاده از واسطی مانند SQL، برعهده دارد. این زبان، مناسب برنامههای انبار داده است که در آن، دادههای نسبتاً ساکن تجزیهوتحلیل میشود، زمان پاسخِ سریع، نیاز نیست و دادهها بهسرعت تغییر نمیکنند.
پایگاه دادههای NoSQL
محیط پایگاه داده NoSQL یک سیستم پایگاه داده غیررابطهای و تا حد زیادی توزیعشده است که امکان تجزیهوتحلیل حجم بالا و انواع متفاوت داده را فراهم میکند. سیستمهای NoSQL این ویژگی را دارند که به صورت افقی مقیاسگذاری میشوند، بنابراین توسعهدهندگان، نگران ذخیرهسازی دادههای با حجم پتابایت و همچنین مشکل تأخیر که در پایگاه دادههای رابطهای وجود دارند، نخواهند بود.
محتوا و فرادادهها: پایگاه دادههای NoSQL میتوانند برای ساخت کاتالوگ محتوا مورد استفاده قرار گیرند. با استفاده از این پایگاه دادهها میتوان دهها میلیون شیء مختلف را ذخیره کرد (محتوای بدون ساختار و فرادادههایی که ممکن است دارای فرمتهای متفاوت یا طول متغیر باشند).
شخصیسازی: پایگاه دادههای NoSQL برای ذخیرهسازی تمامی محصولات و محتوای تولیدشده توسط کاربران استفاده میشوند. این مجموعه دادهها، اپراتورها را قادر میسازند تا محصولات و خدمات خود را مطابق سلیقه مشتری، شخصیسازی کنند.
نتیجهگیری
هماینک، روند رشد داده، کاملاً صعودی و به شکل نمایی است و به باور بسیاری از کارشناسان حوزه داده و کسبوکار باید در انتظار تحولات بسیار گستردهتر در آیندهای نهچندان دور باشیم. چراکه همچنان در ابتدای این مسیر و شیوه صحیح مدیریت آن قرار داریم. این حجم بالا، نهتنها در بهدست آوردن اطلاعات مورد نیاز به کاربران کمک نمیکند، بلکه باعث سردرگمی و ابهام بیشتر آنها نیز میشود. تا آنجا که نیاز به معماری کارآمد برای مدیریت و درنهایت تحلیل آنها به چشم میخورد. برای ورود به دنیای کلانداده، به یک معماری قدرتمند نیاز است که به بحث مصورسازی، بلادرنگ بودن و همچنین تحلیلهای برونخط انجامشده اهمیت دهد. برای انتخاب یک معماری مرجع مناسب کلانداده، انتخابهای بسیاری وجود دارد. داشتن دانش جامع از این مؤلفهها این اطمینان را میدهد که هیچ نقطهضعفی در معماری باقی نماند.
منابع
[1] Deloitte: Opportunities in Telecom Sector: Arising from Big Data (2015)
[2] Wang, J., Yang, Y., Wang, T., Sherratt, R. S., & Zhang, J. (2020). Big data service architecture: a survey. Journal of Internet Technology, 21(2), 393-405.
[3] Guller, M. (2015). Big data analytics with Spark: A practitioner’s guide to using Spark for large scale data analysis. Apress.
پینوشت
[1] Call Detail Record
[2] Fraud detection




