



مسئله پرسش و پاسخ تصویری، یک مسئله چالشبرانگیز است که در سالهای اخیر معرفی شده و مورد توجه بسیاری از محققان دو حوزه پردازش زبان طبیعی و بینایی ماشین، قرار گرفته است. هدف این مسئله، پاسخ به پرسش مطرحشده در مورد تصویر ورودی است. در سالهای اخیر، دستیاران صوتی و عاملهای گفتوگو مانند Cortana، Siri و Alexa در بازار عرضه شدهاند که میتوانند با انسانها با استفاده از زبان طبیعی ارتباط برقرار کنند. روند تحقیقاتی شرکتهای Microsoft و Amazon حاکی از ارتقاء این دستیارهای هوشمند به سمت دستیار تصویری است. علاوه بر این، استفاده از این مسئله در دستیاران صوتی و رباتها، تجربه واقعیتری را برای کاربران ایجاد میکند. در این بررسی، به معرفی مساله پرسش و پاسخ تصویری، کاربرد، اهمیت و چالشهای آن میپردازیم.
واژگان کلیدی: پرسش و پاسخ تصویری، پردازش زبان طبیعی، بینایی ماشین، یادگیری عمیق، مدلهای از قبل آموزشدیده
![]() در سالهای اخیر، پیشرفتهای زیادی در مسائل هوش مصنوعی و یادگیری عمیق که در تقاطع دو حوزه پردازش زبان طبیعی و بینایی ماشین قرار میگیرند، رخ داده است. یکی از مسائلی که اخیراً مورد توجه قرارگرفته، پرسش و پاسخ تصویری است. پرسش و پاسخ تصویری نسخه گسترشیافته مساله پرسش و پاسخ متنی است که در آن، اطلاعات بصری به مساله اضافه شده است[1] شکل زیر گویای تفاوت این دو مسئله است.
در سالهای اخیر، پیشرفتهای زیادی در مسائل هوش مصنوعی و یادگیری عمیق که در تقاطع دو حوزه پردازش زبان طبیعی و بینایی ماشین قرار میگیرند، رخ داده است. یکی از مسائلی که اخیراً مورد توجه قرارگرفته، پرسش و پاسخ تصویری است. پرسش و پاسخ تصویری نسخه گسترشیافته مساله پرسش و پاسخ متنی است که در آن، اطلاعات بصری به مساله اضافه شده است[1] شکل زیر گویای تفاوت این دو مسئله است.
در سیستم پرسشوپاسخ متنی، یک متن و یک سؤال متنی بهعنوان ورودی به سیستم داده میشود و انتظار میرود که سیستم با توجه به درک و تفسیری که از متن و سؤال به دست میآورد، یک جواب متنی را خروجی دهد. اما در سیستم پرسش و پاسخ تصویری، یک تصویر و یک سؤال متنی به ورودی سیستم داده میشود و انتظار میرود که سیستم بتواند با استفاده از عناصر بصری تصویر و تفسیری که از سؤال به دست میآورد، یک پاسخ متنی را در خروجی نشان دهد.
مسئله پرسشوپاسخ تصویری، پیچیدگی بیشتری نسبت به مساله پرسش و پاسخ متنی دارد. زیرا تصاویر، بُعد بالاتر و نویز بیشتری نسبت به متن دارند. علاوه بر این، تصاویر، فاقد ساختار و قواعد دستوری زبان هستند. درنهایت تصاویر غنای بیشتری از دنیای واقعی را ضبط میکنند درحالی که زبان طبیعی در حال حاضر نشانگر سطح بالاتری از انتزاع دنیای واقعی است [1].
مسئله پرسشوپاسخ تصویری یکی از پلههای رسیدن به رؤیای هوش مصنوعی بوده و ازاینجهت حائز اهمیت است. کاربردهای بسیاری برای پرسش و پاسخ تصویری وجود دارد. یکی از مهمترین موارد، دستیار هوشمند برای افراد کمبینا و نابینا است[2]. در حال حاضر این دستیاران با استفاده از صوت و متن این ارتباط را برقرار میکنند؛ درنتیجه گفتوگوی بین این دستیاران با انسانها، مشابه دنیای واقعی نیست. این ارتباط را میتوان با استفاده از دادههای تصویری و ویدئویی به واقعیت نزدیکتر کرد. همین موضوع را میتوانیم بهشکل گستردهتری در رباتها مشاهده کنیم. برای اینکه ربات بتواند بهتر با انسانها ارتباط برقرار کند و به سؤالات و درخواستها پاسخ دهد، نیاز دارد که درک و فهم درستی از اطراف داشته باشد و این، مستلزم داشتن تصویری دقیق از پیرامون است. بنابراین، ربات میتواند برای پاسخ به پرسشها از دانشی که از طریق تصویر پیرامون خود به دست میآورد، جواب درستی را بدهد.

شکل 1: مثالی از سیستم پرسش و پاسخ متنی و تصویری
در مقایسه با مسائل دیگری که مشترک بین پردازش زبان طبیعی و بینایی ماشین است مانند توصیف تصویر و بازیابی متن به تصویر، مسئله پرسشوپاسخ تصویری چالشبرانگیزتر است؛ زیرا:
(1) سؤالات، از پیش تعیین نشده است. به این معنی که در مسالهای مانند تشخیص اشیا، سؤال این است که چه اشیایی در تصویر وجود دارد و این سؤال از پیش تعیین شده است و در طول حل مساله تغییر نمیکند و تنها تصویر، تغییر میکند که منجر به پاسخهای متفاوت میشود؛ اما در پرسش و پاسخ تصویری، برای هر تصویر، سؤالات متفاوت و مرتبط با همان تصویر پرسیده میشود که در زمان اجرا تعیین میشود.
(2) اطلاعات موجود در تصویر، ابعاد بالایی دارد که پردازش آنها به زمان و حافظه زیادی نیاز دارد.
(3) مسئله پرسشوپاسخ تصویری نیاز به حل مسائل پایهای و فرعی دارد؛ مانند تشخیص اشیا، تشخیص فعالیت، طبقهبندی صفات، شمارش، طبقهبندی صحنه و روابط مکانی بین اشیا [3].
 روشهای حل مسئله پرسشوپاسخ تصویری
روشهای حل مسئله پرسشوپاسخ تصویری
بسیاری از محققان، راهحلها یا الگوریتمهایی را برای حل مساله پرسش و پاسخ تصویری پیشنهاد کردهاند که ما آنها را به دو رویکرد کلی تقسیم میکنیم: رویکرد یادگیری عمیق[3]، رویکرد شبکههای از قبل آموزشدیده روی زبان طبیعی و تصویر[4].
 رویکرد یادگیری عمیق
رویکرد یادگیری عمیق
اکثر روشهای پیشنهادشده در رویکرد یادگیری عمیق، دارای سه فاز هستند[3]. فاز اول این فرآیند، استخراج ویژگی از تصویر و سؤالات است که راهحلهای موفق در این فاز، ریشه در روزهای باشکوه یادگیری عمیق دارد زیرا بیشتر راهحلهای موفق در این حوزه از مدلهای یادگیری عمیق استفاده میکنند مانند CNNها برای استخراج ویژگی از تصویر و RNN ها و انواع آن ( LSTM و GRU) برای استخراج ویژگی از سؤالات. VGGNet و ResNet دو نمونه از شبکههای کانولوشنی هستند که بهطور گستردهای در سیستمهای پرسش و پاسخ تصویری برای استخراج ویژگی از تصویر مورد استفاده قرار گرفتهاند. محققان حوزه پرسش و پاسخ تصویری، ترجیح میدهند که برای استخراج ویژگی از متن و بازنمایی آن از LSTM استفاده کنند. آنها معتقدند که RNN ها عملکرد بهتری نسبت به روشهای مستقل از دنباله کلمات مانند word2vec دارند. اما آموزش RNNها نیاز به دادههای برچسب خورده زیادی دارد. در فاز دوم که مهمترین و اصلیترین فاز است، ویژگیهای استخراجشده از تصویر و سؤال با هم ترکیب میشوند. سپس از ترکیب ویژگیها برای پیشبینی پاسخ نهایی در فاز سوم استفاده میشود. بهطورکلی میتوان روشهای ترکیب ویژگی را به سه بخش تقسیم کرد:
روشهای پایه: سادهترین و پایهایترین روشها برای ترکیب ویژگیها concatenation، جمع متناظر ویژگیها و ضرب متناظر ویژگیها است.
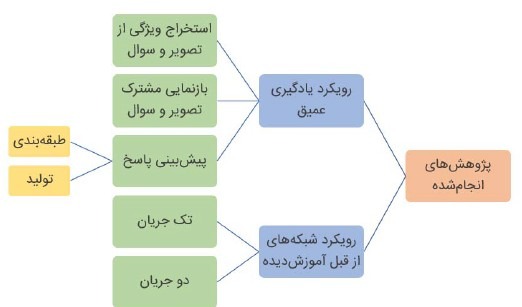
شکل 2: نمودار روشهای پیشنهاد شده و مراحل آن برای حل مسئله پرسشوپاسخ تصویری
روشهای مبتنی بر شبکههای عصبی: در این روشها، محققان شبکههای عصبی را با لایههای خاص برای ترکیب ویژگیهای تصویر و سؤال آموزش میدهند. ساختار و عملکرد این لایه ممکن است برای مدلهای مختلف پیشنهادشده متفاوت باشد.
روشهای مبتنی بر مکانیزم توجه: در پنج سال گذشته، روشهای بسیاری در مساله پرسش و پاسخ تصویری مطرح شده که اساس کار آنها بر پایه مکانیزم توجه است. مدلهای مبتنی بر مکانیزم توجه به ناحیههایی از تصاویر که مربوط به سؤال است، توجه میکنند. مدلهای موجود در این رویکرد یا به تصویر و یا به سؤال و یابه هر دو توجه میکنند (شکل 3).
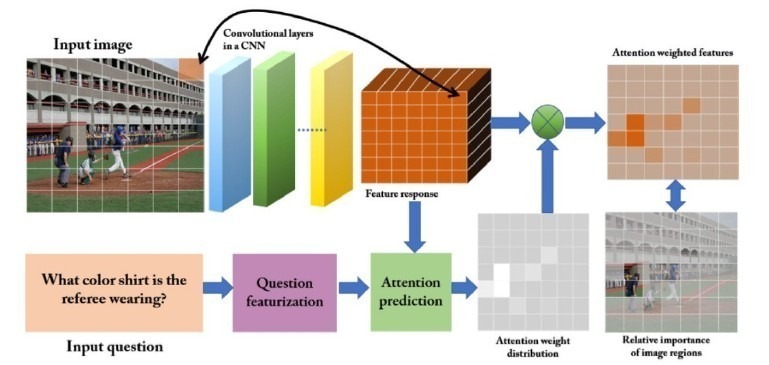
شکل 3: سیستم پرسشوپاسخ تصویری مبتنی بر مکانیزم توجه
در فاز آخر، از بازنمایی مشترک بین تصویر و سؤال برای به دست آوردن پاسخ در خروجی استفاده میشود. بدین منظور از دو رویکرد طبقهبندی و تولید بهره میبرند. در رویکرد طبقهبندی، مجموعهای از پیش تعیینشده از پاسخهای کاندید آماده میشود و هرکدام از پاسخهای کاندید بهعنوان یک کلاس در نظر گرفته شده و پاسخی که بیشترین احتمال را داشته باشد بهعنوان پاسخ پیشبینی شده مدل در نظر گرفته میشود. در رویکرد تولید پاسخ، معمولاً از بازنمایی مشترک تصویر و سؤال استفاده و یک جمله بهعنوان پاسخ در خروجی تولید میشود.
رویکرد مدلهای از قبل آموزشدیده روی زبان طبیعی و تصویر
در سالهای اخیر شاهد ظهور شبکههای از قبل آموزشدیده تنها روی دادههای تصویری مثل ResNet و یا تنها روی دادههای متنی مانند BERT، GPT-2 و GPT-3 بودهایم. استفاده از این شبکهها منجر به بهبود مسائل موجود در بینایی ماشین و پردازش زبانهای طبیعی شده است. با الهام از این موضوع، مدلهای از قبل آموزشدیده روی زبان طبیعی و تصویر نیز ایجاد شدند که هدف آنها تولید بازنمایی مشترک دادههای تصویری و دادههای زبانی است (شکل 4). معماری شبکههای از قبل آموزشدیده روی زبان طبیعی و تصویر بهطورکلی به دو دسته تکجریان و دوجریان تقسیم میشود[4].
معماری تکجریان: پایه و اساس این معماری شبیه معماری مدل BERT است که رمزگذاری متن و رمزگذاری تصویر را به طور همزمان انجام میدهد. درواقع برای یادگیری بازنمایی متن و تصویر از یک رمزگذار استفاده میکند. برای مثال، تصویر به همراه یک جمله توصیفکننده آن و یا یک فیلم به همراه زیرنویسش به این شبکهها برای آموزش داده میشود. از بازنماییهای آموختهشده توسط این مدلها در مسائل پاییندستی understanding و یا generation استفاده میشود.
معماری دوجریان: در مقابل معماری تکجریان، معماری دوجریان برای یادگیری هرکدام از بازنماییهای تصویر و متن از یک رمزگذار مستقل استفاده میکند. سپس از یک رمزگذار دیگر برای بهدست آوردن بازنمایی مشترک متن و تصویر استفاده میکند.
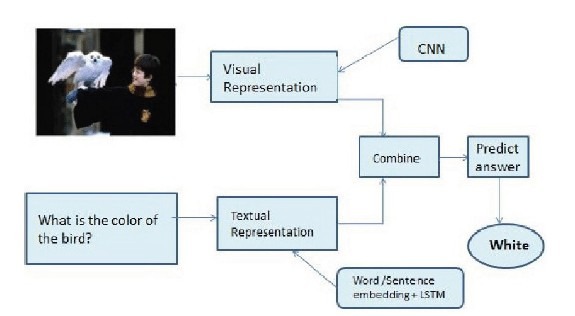
شکل 4: کارکرد شماتیک سیستم پرسشوپاسخ تصویری با رویکرد مدلهای از قبل آموزشدیده بر روی زبان طبیعی و تصویر
نتیجهگیری
با وجود اینکه از معرفی مسئله پرسش و پاسخ تصویری تنها چندین سال میگذرد، رشد آن در این چند سال قابل توجه بوده است. مجموعه دادگان بسیاری با اهداف مختلف در این سالها معرفی شده و با معرفی شبکههای از قبل آموزشدیده، بهبود چشمگیری در مسائل یادگیری عمیق رخ داده است. طوری که بیشتر مسائل مختلف در یادگیری عمیق، بهترین نتیجه خود را با استفاده از شبکههای از قبل آموزشدیده به دست آوردهاند. مسئله پرسشوپاسخ تصویری نیز از این قاعده مستثنی نیست و در حال حاضر شبکههای از قبل آموزشدیده روی زبان طبیعی و تصویر، بهترین عملکرد را برای مجموعه دادگان پرسش و پاسخ تصویری رقم زدهاند.
از طرفی مدلهای پیشنهاد شده فعلی در این حوزه با نواقصی مواجه هستند که به مرور باید در آینده رفع شوند. اولین مشکل روشهای فعلی، پاسخ به سؤالاتی است که نیاز به استدلال طولانی دارند. از طرفی، منبع بهبودهای نسبی مدلهای موجود واضح نیست و مشخص نیست که مدل تا چه اندازه مفاهیم مشترک بین زبان و تصویر را درک میکند و چگونه از پیوند این دو برای پیشبینی پاسخ استفاده میکند. پس اگر بتوانیم بفهمیم که روند درک مدلهای فعلی از زبان و تصویر چگونه است، میتوانیم مدلی را پیشنهاد دهیم که بتواند به سؤالاتی که نیاز به استدلال طولانی دارند، پاسخ دهد.
اکثر روشهای پیشنهادشده، مسئله پرسش و پاسخ تصویری را یک مساله طبقهبندی در نظر میگیرند و تعداد کمی از کارهای انجامشده به دنبال تولید پاسخ بودهاند. یکی از دلایلی که باعث کمتوجهی به تولید پاسخ شده است، زمانبر بودن فرآیند آن است. یکی از راهحلهای این مشکل میتواند استفاده از ترنسفرمرها با چندین لایه رمزگذار و رمزگشا روی هم باشد. همچنین از معماری ترنسفرمر برای تولید پاسخ در پرسش و پاسخ تصویری استفاده شده است.
یکی دیگر از محدودیتهای مسئله پرسشوپاسخ تصویری، فقدان مجموعه دادگان متناسب با واقعیت است. در حال حاضر نمیتوان از دادگان موجود در مسئله پرسشوپاسخ تصویری برای کاربردهای عملی مانند کمک به افراد نابینا و کمبینا استفاده کرد. از طرف دیگر اکثر مجموعه دادگان با مشکل بایاس مواجه هستند؛ بنابراین تهیه و جمعآوری دادگان برای مسئله پرسشوپاسخ تصویری و آموزش یک مدل کارآمد که فاقد مشکلات ذکر شده باشد، کار بسیار ارزشمندی خواهد بود و مسیر جدیدی را برای سایر محققان باز خواهد کرد.
منابع
[1] Q. Wu, D. Teney, P. Wang, C. Shen, A. Dick, and A. van den Hengel, “Visual question answering: A survey of methods and datasets,” Comput. Vis. Image Underst., vol. 163, pp. 21–40, 2017, doi: 10.1016/j.cviu.2017.05.001.
[2] D. Gurari et al., “VizWiz Grand Challenge: Answering Visual Questions from Blind People,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., pp. 3608–3617, 2018, doi: 10.1109/CVPR.2018.00380.
[3] S. Manmadhan and B. C. Kovoor, “Visual question answering: a state-of-the-art review,” Artificial Intelligence Review. 2020, doi: 10.1007/s10462-020-09832-7.
[4] A. Mogadala, M. Kalimuthu, and D. Klakow, “Trends in integration of vision and language research: A survey of tasks, datasets, and methods,” arXiv, no. 1,1–127, 2019.




