



محاسبات با حفظ حریم خصوصی، گروهی از سیستمها، فرآیندها و تکنیکهایی هستند که پردازش را قادر میسازد تا از دادهها ارزش بهدست آورد درحالی که حریم خصوصی و امنیت برای افراد حفظ میگردد. انواع روشهای نرم افزاری و سخت افزاری برای محافظت از دادهها وجود دارد. برخی از نمونهها عبارتند از: محاسبات چند جانبه ایمن ، رمزگذاری همومورفیک ، اثبات دانش صفر و محیط اجرایی قابل اعتماد (TEE). هر تکنیک مزایا و معایب خود را داشته و با چالش نحوه محافظت ایمن از دادههای در حال استفاده دست و پنجه نرم میکند. PETها به طرق مختلف به حفظ حریم خصوصی و دادهها کمک میکنند. دسته اول PETها ابزارهایی هستند که دادهها را تغییر میدهند. گروه دیگری از PETها به جای تغییر دادن دادهها ، بر پنهان کردن یا محافظت از دادهها تمرکز میکنند. و در نهایت، دسته سوم سیستمها و معماری دادههای جدید را برای پردازش، مدیریت و ذخیره دادهها نشان میدهد.
کلمات کلیدی: محاسبات با حفظ حریم خصوصی، تکنولوژی حفظ حریم خصوصی، تغییر داده، حفاظت داده.
![]() تا سال 2025، حدود 60 درصد از سازمانهای بزرگ از یک یا چند تکنیک محاسبات با حفظ حریم خصوصی در تجزیهوتحلیل، هوش تجاری یا رایانش ابری استفاده خواهند کرد.”گارتنر محاسبات با حریم خصوصی را به عنوان یک روند کلیدی فناوری سازمانی برای سال 2022 معرفی کرده است.
تا سال 2025، حدود 60 درصد از سازمانهای بزرگ از یک یا چند تکنیک محاسبات با حفظ حریم خصوصی در تجزیهوتحلیل، هوش تجاری یا رایانش ابری استفاده خواهند کرد.”گارتنر محاسبات با حریم خصوصی را به عنوان یک روند کلیدی فناوری سازمانی برای سال 2022 معرفی کرده است.
ارزش واقعی دادهها صرفاً در داشتن آنها نیست، بلکه در نحوه استفاده از آن برای مدلهای هوش مصنوعی و تجزیهوتحلیل است.
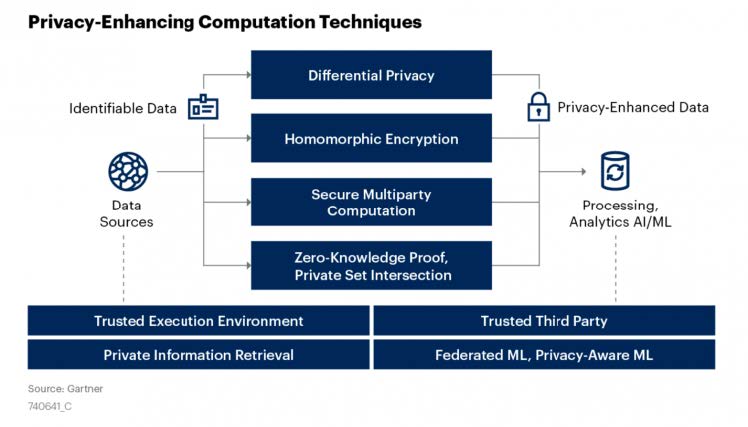
شکل 1: مدل بررسیشده در گارتنر
روشهای محاسبات با حفظ حریم خصوصی (PEC) اجازه میدهد که دادهها در بین اکوسیستمها به اشتراک گذاشته ضمن ایجاد ارزش، حریم خصوصی نیز حفظ شود.
 تکنیکهای حفظ حریم خصوصی
تکنیکهای حفظ حریم خصوصی
PETها به طرق مختلف به حفظ حریم خصوصی و دادهها کمک میکنند. دسته اول PETها ابزارهایی هستند که دادهها را تغییر میدهند. این دسته معمولاً به دنبال برهم زدن یا قطع رابطه بین دادهها و فردی که با آنها در ارتباط است هستند. گروه دیگری از PETها به جای تغییر دادن دادهها بر پنهان کردن یا محافظت از دادهها تمرکز میکنند. رمزنگاری نمونهای از این نوع است زیرا فرمت دادهها را تغییر میدهد، اما بهجای تغییر دائمی، آنها را موقتاً پنهان میکند. درنهایت، دسته وسیعی از PETها وجود دارد که سیستمها و معماری دادههای جدید را برای پردازش، مدیریت و ذخیره دادهها نشان میدهد. برخی از این سیستمها ، دادهها را برای محاسبات یا ذخیرهسازی تجزیه میکنند در حالی که برخی دیگر لایههای مدیریتی را برای ردیابی و ممیزی فراهم مینمایند که اطلاعات کجا و برای چه هدفی جریان دارد.
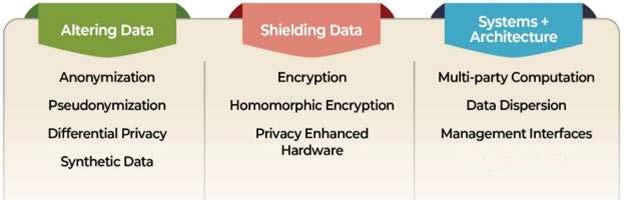
شکل 2: روشهای افزایش حریم خصوصی
تغییر دادهها
هویتزدایی دادهها[1] یک اصطلاح فراگیر شامل انواع روشها و ابزارهایی برای شناسایی خصوصیات مجموعه دادهها میباشد. بسیاری از فعالیتهای داده نیازی به شناسایی مستقیم افراد یا پیوند دادن آنها به دادههای مرتبط ندارند. برای مثال، واحدها ممکن است فقط نیاز به درک آمار توصیفی، مانند میانگینها، یا نحوه تعامل مشتریان با محصولات به عنوان یک گروه داشته باشند. برای اینگونه موارد میتوان دادهها را بهطور دائم تغییر داد[2] تا پتانسیل ربط دادن آنها به یک فرد کاهش یابد. در ادامه روشهایی از هویتزدایی مورد بررسی قرار میگیرد.
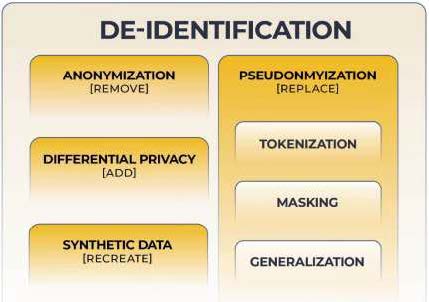
شکل 3: هویتزدایی
ناشناسسازی
اصطلاح ناشناسسازی[3] به طور گسترده در بحثهای مربوط به حفظ حریم خصوصی استفاده میشود و به طور کلی میتواند به معنای هویت زدایی باشد. ناشناسسازی یکی از تکنیکهای اصلی افزایش حریم خصوصی است که در صنایع و سازمانها استفاده میشود، هرچند که ثابت شده است اگر چندین منبع داده ترکیب شوند، نسبتاً ناامن است. حذف شناسهها از دادهها میتواند یک فرآیند دستی یا خودکار باشد. برای فرآیندهای خودکار، تأیید اینکه اطلاعات صحیح، در حال حذف شدن است مهم است.
مشکل اصلی ناشناس سازی این است که اطلاعات حذف شده از مجموعه دادهها را میتوان با ترکیب اطلاعات از منابع مختلف بازسازی کرد. در دهه 1990، دکتر لاتانیا سوینی دریافت که دادههایی که شناسههای مستقیم (نام، آدرس، شماره تلفن و غیره) را حذف میکنند، هنوز هم میتوانند برای شناسایی افراد هنگام ترکیب با پایگاههای داده دیگر، از جمله آنهایی که در دسترس عموم هستند، استفاده شوند. وی دریافت که 87٪ از جمعیت ایالات متحده را میتوان تنها با استفاده از تاریخ تولد، جنسیت و کد پستی آنها شناسایی کرد.
قوانین جدید، مانند GDPR، این ضعف را تصدیق میکند و حذف اطلاعات را به اندازه کافی قوی برای هویت زدایی نمیداند.
مستعارسازی
مستعارسازی[4] فرآیندی است که طی آن بخشهای از اطلاعات که سری تلقی میشوند توسط مقادیری تصادفی جایگزین میشوند. این روش در کنار راههای دیگری همچون رمزنگاری دادهها، به منظور حفاظت از اطلاعات شخصی افراد ،حریم خصوصی آنها و به طور کلی افزایش سطح امنیت استفاده میشود.
توکنسازی[5]، پوشاندن[6] و عمومیسازی[7] روشهای مختلف مستعار سازی هستند. در حالی که این روشها متفاوت هستند، اما یک ویژگی مشترک دارند و آن اینکه به جای اطلاعات حساس و قابل شناسایی از اطلاعات ساختگی استفاده میشود در عین حال قابل استفاده هم هستند و به همین دلیل امکان پردازش و تجزیه و تحلیل مداوم دادهها پس از مستعار سازی نیز فراهم است.
توکنسازی داده حساس را با یک توکن جایگزین میکند. توکنها معمولاً رشتههای تصادفی از اعداد و حروف هستند و در بسیاری از موارد قابل برگشت میباشند. یک موجودیت کلیدی خواهد داشت که توکنها را با اطلاعات واقعی آنها مطابقت میدهد.
استفاده رایج از توکنسازی در سیستمهای پرداخت است. هنگامی که یک مصرف کننده کارت اعتباری را میکشد، آن عدد با یک توکن جایگزین شده و تنها توکن ذخیره میشود.
شبکههای کارت دارای کلیدی هستند که بدانند کدام توکن با شماره کارت واقعی یک فرد مرتبط است.
پوشاندن مانند توکنسازی است، قطعات داده را با رشتههای تصادفی از اعداد و/یا حروف جایگزین میکند. یک تفاوت کلیدی بین توکنسازی و پوشاندن این است که پوشاندن معمولاً برای دادههای در حال پردازش اعمال میشود و دائمی میباشد. پردازش ممکن است شامل ایجاد، ویرایش، حذف، مشاهده یا چاپ داده باشد.
عمومیسازی یک تکنیک متفاوت است که یک عبارت عمومی را به جای یک عبارت خاص وارد میکند. معمولاً در شناسههای غیر مستقیم استفاده میشود. به عنوان مثال، به جای افشای سن واقعی یک فرد، یک پایگاه داده عمومی شده ممکن است هر فرد را به یک محدوده سنی، مانند «18-30» یا «31-45» اختصاص دهد.
K-Anonymization یک تکنیک مرتبط است که تعداد خطوطی را که باید عمومی شوند تا اینکه هیچ فردی نتواند از یک گروه بزرگ متمایز شود تعیین میکند.
مستعار سازی بسیار بالغ است و چندین استاندارد برای این تکنیکها وجود دارد. برای مثال، شورای استانداردهای امنیتی صنعت پرداخت (PCI SSC)، توکنسازی را روشی تایید شده برای محافظت از دادههای کارت میداند.
متأسفانه، مانند ناشناسسازی که در بالا توضیح داده شد، این روشها بهطور خودکار حریم خصوصی ایجاد نمیکنند، حتی اگر اطلاعات حساس و قابل شناسایی مانند شماره کارت اعتباری مبهم شوند.
محققان MIT دریافتند که میتوانند افراد را بر اساس فراداده یا جزئیات توصیفی مرتبط با تراکنشهای کارتشان علیرغم استفاده از توکنها، شناسایی کنند.
حریم خصوصی تفاضلی
حریم خصوصی تفاضلی[8] به جای حذف یا تغییر عناصر داده به شناسههای مبهم، دادههای تصادفی، اضافی یا «نویز» را اضافه میکند. هدف از حریم خصوصی تفاضلی اضافه کردن دادههای تصادفی و اضافی به اندازه کافی است تا اطلاعات واقعی در میان نویز پنهان شود. حفظ حریم خصوصی تفاضلی امکان تجزیه و تحلیل دقیق روی دادهها را به صورت کلی فراهم میکند، زیرا علیرغم نویز اضافه شده، دادههای ترکیبی میتوانند سیگنالهای دقیقی ارائه دهند.
یکی از مزایای حریم خصوصی تفاضلی این است که شناسایی مجدد با ترکیب مجموعه دادهها دشوار است زیرا مهاجم نمیداند کدام اطلاعات درست است.
دادههای مصنوعی
شکل دیگری از تغییر دادهها برای محافظت از حریم خصوصی، ایجاد دادههای کاملاً جدید و مصنوعی است. این گامی فراتر از مستعار سازی است، که دادههای واقعی را با دادههای تغییر یافته جایگزین میکند، یا حریم خصوصی تفاضلی، که اطلاعات اضافی و جعلی را در مجموعه دادههای واقعی وارد میکند. دادههای مصنوعی معمولاً از طریق یادگیری ماشین ایجاد میشوند و ویژگیهای دادههای دنیای واقعی را تقلید میکنند.
دادهها با تغذیه دادههای واقعی در الگوریتمهای یادگیری ماشین ایجاد میشوند، که ویژگیها و روندها را شناسایی میکنند و آنها را در اطلاعات مصنوعی تکرار میکنند. مزیت اصلی استفاده از دادههای مصنوعی[9]این است که میتوان آن را برای موارد استفاده مختلف سفارشی کرد و در عین حال نیاز به جمع آوری و ذخیره اطلاعات واقعی در مورد افراد را محدود نمود. دادههای مصنوعی را میتوان برای آموزش مدلهای دیگر یا برای آزمایش سیستمهای جدید استفاده کرد.
یکی از اشکالات اصلی دادههای مصنوعی، وابستگی آن به کیفیت دادههای اصلی است که برای آموزش سیستمهای یادگیری ماشین استفاده شده است. ممکن است در داده اصلی سوگیری وجود داشته باشد یا ممکن است نماینده دادههای مورد نظر نباشد و دادههای مصنوعی آن مسائل را تکرار کند.
محافظت از داده
فناوریهای حفظ حریم خصوصی که از دادهها محافظت میکنند، اطلاعات اصلی را تغییر نمیدهند. در عوض، آن دادهها را در زمانهای خاصی نامفهوم یا غیرقابل استفاده میکنند تا از دسترس اشخاص غیرمجاز به آن جلوگیری گردد.
برای PETهایی که از دادهها محافظت میکنند، مهم است که سه حالت مختلف محافظت از دادهها[10] متمایز گردند: در حالت استراحت[11]، در حال استفاده [12]یا در حال انتقال[13]. روشهای مختلفی برای محافظت از دادهها وجود دارد.
در ادامه به اختصار به برخی از این تکنولوژیها خواهیم پرداخت :
رمزنگاری
قابل تشخیصترین و رایجترین شکل محافظت از دادهها، رمزگذاری است. رمزگذاری یک فرآیند برگشتپذیر است که دادهها را به شکل نامفهومی به نام متن رمز تبدیل میکند. رمزگشایی متن رمز، دادهها را به شکل اصلی خود (که به آن متن ساده میگویند) تبدیل میکند.
هدف از رمزگذاری و رمزگشایی این است که فقط کاربران مجاز برای دسترسی به متن ساده با استفاده از یک کلید برای تبدیل، دسترسی داشته باشند. حتی اگر کاربران غیرمجاز به دادههای رمزگذاری شده یا متن رمز شده دسترسی پیدا کنند، بدون دسترسی به کلید قادر به خواندن آن نخواهند بود.
رمزنگاری همومورفیک
در حالی که رمزگذاری سنتی میتواند دادهها را در حالت استراحت و در حین انتقال ایمن کند، رمزگذاری همومورفیک میتواند از دادههای در حال استفاده محافظت کند. محافظت از دادههای در حال استفاده دشوارتر از دو حالت دیگر است زیرا هنوز باید دادهها برای پردازش قابل درک باشند. رمزنگاری همومورفیک قابلیت استفاده از دادهها را در زمانی که محافظت میشود حفظ میکند. در این تکنیک همچنان یک کلید معمولا نامتقارن وجود دارد که برای رمزگشایی اطلاعات استفاده میشود، اما دادهها میتوانند در طول پردازش محافظت شوند.
این تکنیک هنوز در مراحل اولیه بلوغ خود است اما این پتانسیل را دارد که به طور گسترده در برنامههای کاربردی مختلف از قراردادهای هوشمند گرفته تا پردازش پرداخت مورد استفاده قرار گیرد. برخی از شرکتهای مبتنی بر فناوری شروع به استفاده مستقیم از این تکنیک در محصولات خود کردهاند. به عنوان مثال، رمزگذاری همومورفیک برای نظارت بر اینکه آیا گذرواژههای ذخیرهشده در مرورگرها در معرض نقض دادهها قرار گرفتهاند یا خیر، استفاده میشود. با این حال، رمز عبور در طول این تجزیه و تحلیل رمزگذاری شده باقی میماند. شکلهای مختلفی از رمزگذاری همومورفیک وجود دارد که بر اساس پیچیدگی محاسباتی که روی دادهها انجام میشود متفاوت هستند. دستهبندی HE شامل سه دسته زیر میباشد:
- partially homomorphic encryption
- somewhat homomorphic encryption
- fully homomorphic encryption
افزایش حریم خصوصی سختافزاری
تولیدکنندگان رایانه بهطور فزایندهای ویژگیهای غیرقابل عرضه و افزایشدهنده حریم خصوصی را در خطوط تولید خود برای رسیدگی به موارد استفاده تجاری و شخصی معرفی میکنند[14]. صرفنظر از کاربرد اصلی، این نوع سختافزار برای محافظت از دادههایی که در دستگاهها جریان مییابند، مستقر میشوند.
نمونههایی از سختافزارهای افزایشدهنده حریم خصوصی عبارتاند از:
- صفحهنمایشهای حریم خصوصی که محتوای صفحه نمایش را از همه به جز کاربر مخفی میکند.
- احراز هویت بیومتریک، از جمله اثر انگشت و/یا تشخیص چهره.
- مکانیسمهای Anti-interdiction که دستکاری سختافزار و نرمافزار را تشخیص میدهند این دستکاری ممکن است در حین چرخه انتقال دستگاه از سازنده به کاربر نهایی رخ دهد.
سیستمها و معماری
دسته نهایی PETها سیستمها و فرآیندهای جدید برای فعالیتهای دادهای است.سیستمها و معماریها[15] به جای تغییر دادن دادهها یا محافظت از آن، راههای امنتر و حفظ حریم خصوصیتری را برای مدیریت اطلاعات ایجاد میکنند. برخی از این سیستمها همچنین شفافیت و نظارت بیشتری را بر روی فعالیتهای داده از جمله جمع آوری، پردازش، انتقال، استفاده و ذخیرهسازی امکانپذیر میکنند.
محاسبات چندجانبه
محاسبات چندجانبه[16]، تکنیکی است که موجودیتهای مختلف را قادر میسازد تا بدون افشای اطلاعات کامل با دادهها تعامل داشته باشند. این تکنیک دادهها را در چندین «اشتراک» تعیین میکند که توسط نهادهای مختلف توزیع و تحلیل میشوند. تقسیم اطلاعات به این معنی است که اگر هر نهادی در معرض خطر قرار گیرد، مجموعه کامل دادهها در معرض خطر قرار نمیگیرد.
محاسبات چند طرفه را نیز میتوان با تکنیکهایی مانند رمزگذاری همومورفیک که توضیح داده شد ترکیب کرد، بنابراین حتی “اشتراکها” در طول تجزیه و تحلیل دادهها آشکار نمیشوند.
استفاده از محاسبات چند جانبه در میان دادههای توزیعشده از قبل، این مزیت را دارد که هرگز آنها را در یک مخزن مرکزی ترکیب نمیکند، در نتیجه ریسک را خیلی بیشتر کاهش میدهد.
محاسبات چند جانبه یک تکنولوژی بالغ است و امروزه بسیاری از سازمانهای تحقیقاتی از آن استفاده میکنند.
پراکندگی دادهها
پراکندگی داده[17] به فرآیندی اطلاق میشود که در آن دادهها به قطعات کوچکتر تقسیم میشوند و در یک زیرساخت ذخیرهسازی توزیعشده نگهداری میشوند که معمولاً چندین مکان جغرافیایی را در بر میگیرد.
در این فرآیند، از نرم افزار برای شکستن فیلدهای داده به صورت تصادفی استفاده میشود. پراکندگی دادهها میتواند امنیت دادهها و حفظ حریم خصوصی را افزایش دهد، زیرا اگر یک مکان ذخیرهسازی مورد تعرض قرار گیرد یا به فایلهای آن دسترسی پیدا شود، اطلاعات بدون قطعات باقی مانده، کامل یا قابل درک نخواهد بود.
رابطهای مدیریتی
از آنجایی که شرکتها دادهها را جمعآوری میکنند، برای قابل دسترس کردن و عملیاتی کردن اطلاعات به سیستمهای تجاری نیاز است. نهادها ممکن است بخواهند دادهها را متمرکز کنند یا سیستمها را پیوند دهند تا دادهها را در واحدهای تجاری قابل استفاده کنند و در عین حال محرمانه بودن اطلاعات را نیز حفظ کنند. رابطهای مدیریتی[18]، سیستمهای نرمافزاری هستند که بین مجموعه دادهها یا پایگاههای داده و کارمندان یا نهادهایی که به آن مجموعه دادهها یا پایگاههای داده دسترسی دارند قرار میگیرند.
یکی از عناصر مهم این نوع سیستمها، توانایی آنها در شناسایی انواع داده، برچسب گذاری اطلاعات یا افزودن ابرداده است که ویژگیهای خاصی از دادهها را توصیف میکند، مانند حساسیت. برای مثال، اگر اطلاعات به عنوان حساس شناسایی شود، سیستمها میتوانند سایر تکنیکهای افزایش حریم خصوصی را بهطور خودکار و بدون دخالت انسان انجام دهند، مانند تغییر دادهها.
نتیجهگیری
فناوریهای تقویتکننده حریم خصوصی مجموعهای از ابزارهای جذاب و هیجانانگیز هستند که میتوانند به جذب ارزش دادهها و حفظ امنیت، محرمانگی و خصوصی بودن آنها کمک کنند. علیرغم این پتانسیل، PETها راه حلهای مستقلی برای نگرانیهای حفظ حریم خصوصی و امنیتی نیستند و باید همراه با سیاستهای قوی و سیستمهای حاکمیتی مورد استفاده قرار گیرند. از آنجایی که رگولاتورها ، سیاستگذاران و کسبوکارها این فضا را بررسی میکنند، درک تنوع تکنیکها و سیستمهایی که PETها را تشکیل میدهند و همچنین نقاط قوت و اهداف مختلف آنها مهم است.
منابع
[1] Burke, Brian, P. H. (2020). Top Strategic Technology Trends for 2021- Gartner. Gartner, 1–12. https://digital-strategy.ec.europa.eu/en/library/communication-artificial-intelligence europe%0A https://digital-strategy.ec.europa.eu/en/library/communication-artificial-intelligence-europe%0Ahttps://ec.europa.eu/digital-single-market/en/news/communicatio
[2] Kaitln Asrow, F. P. A., & Spiro Samonas, S. R. S. (n.d.). Privacy Enhancing Technologies: Categories, Use Cases, and Considerations. Federal Reserve Bank of San Francisco,. https://www.frbsf.org/banking/publications/fintech-edge/2021/june/privacy-enhancing-technologies/Privacy-Enhancing-Technologies_FINAL_V2_TOC-Update.pdf
پینوشت
[1] Data de-identification
[2] Altering data
[3] Anonymization
[4] Pseudonymization
[5] tokenization
[6] masking
[7] generalization
[8] Differential Privacy
[9] Synthetic Data
[10] shielding data
[11] at-rest
[12] in-use
[13] in-transit
[14] Privacy Enhanced Hardware
[15] systems and architectures
[16] Multi-Party Computation
[17] Data dispersion
[18] Management Interfaces




