



هشدار امنیتی در خصوص لزوم ایجاد آزمایشگاههای ارزیابی امنیتی محصولات هوشمصنوعی
امروزه شبکههای عصبی بهعنوان یکی از بهترین ابزارهای مطرح در هوشمصنوعی و یادگیری ماشین شناخته شدهاند و در انجام کارهای متنوع مورد استفاده قرار میگیرند. در سالهای اخیر موارد متعددی از آسیبپذیری این شبکهها مطرح شده است [1]–[20]. این آسیبپذیریها غالباً با افزودن اختلالات و تغییرات بسیار اندک بهصورت جمعشونده و غیر جمعشونده در داده ورودی ایجاد میشوند. این اختلالات موجب میشوند که با وجود نامحسوس بودن تغییرات اعمال شده در ورودی از دیدگاه عامل انسانی، خروجی مدلهای آموزش دیده تغییر یابند. ناکارآمد شدن این شبکهها به دلیل شکست در مقابل حملات خصمانه موجب گردیده است که توجه برخی از پژوهشگران فعال در عرصه یادگیری عمیق به بررسی و تحلیل دقیقتر این شبکهها و مقاومسازی آنها نسبت به اینگونه حملات معطوف گردد.

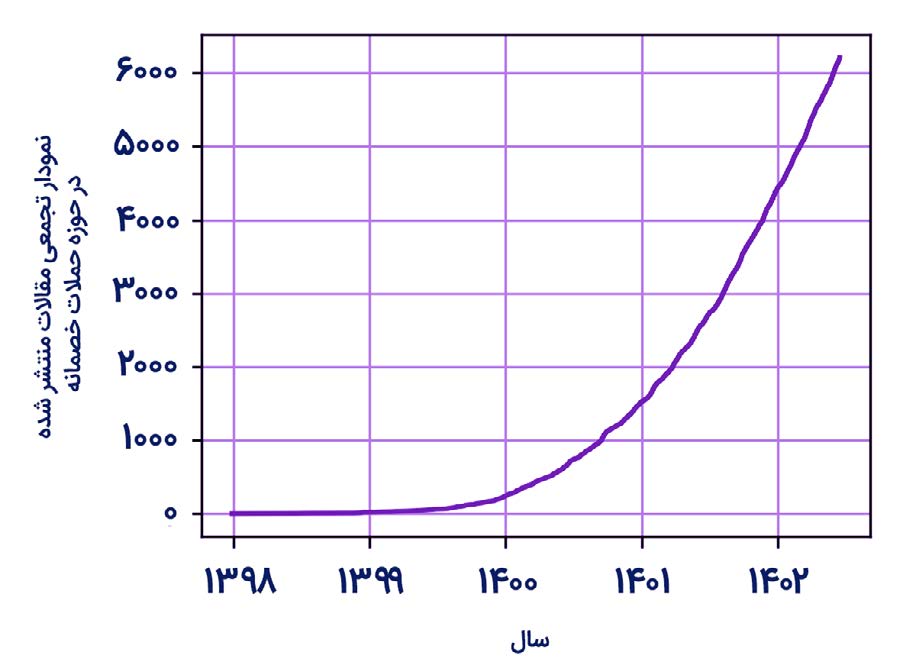
تصویر 1: نمودار تجمعی مقالات منتشر شده در حوزه حملات خصمانه
به مجموعهای از عملیات خصمانه که موجب شوند تا بدون تغییر محسوس داده از دیدگاه انسانی، مدل هوشمصنوعی در تعیین کلاس داده دچار اشتباه شود حمله گفته میشود. در روشهای حمله به دنبال شناسایی راهحلها و روشهای تغییر داده ورودی و فریب مدلهای هوشمصنوعی و در نتیجه تغییر کلاس خروجی مدل میباشند [1], [2].
از جنبههای مثبت حمله به مدلهای هوشمصنوعی، همانند هدف هکرهای کلاهسفید میتوان جهت ارزیابی و شناسایی آسیبپذیری[1] مدلهای هوشمصنوعی استفاده کرد.
نمونه سادهای از حملات در در شکل 1 به تصویر کشیده شده است. همانطور که از سمت چپ به راست مشاهده میشود تصویر ورودی توسط یک مدل دستهبندی هوشمصنوعی با دقت 89% «لیوان یا ماگ» تشخیص داده شده است. پس از افزودن میزان بسیار کمی (0.0008) اختلال خصمانه، تصویر حاصل شده سمت راست با اینکه از نگاه عامل انسانی همچنان همان کلاس قبلی (لیوان، ماگ) را خواهد داشت اما اینبار همان مدل هوشمصنوعی قبلی، تصویر حاصل را با دقت %99.3 «اتوموبیل» تشخیص داده است. این تغییر و اختلال ساده که به ظاهر دیده نمیشود ولی توانسته خروجی مدل را تغییر دهد میتواند آسیبپذیری مدلهای هوشمصنوعی را بیش از پیش نشان دهد.

تصویر 2: نمونه یک حمله و تغییر کلاس
با توجه به آنچه تاکنون بیان شده است، به تغییرات بسیار اندک که در عین نامحسوس بودن از دیدگاه عامل انسانی، از نظر مدل یادگیری ماشینی موجب تغییر کلاس داده شود، اختلال گویند. اغلب پیداکردن یک اختلال مناسب، نیازمند حل مسئله بهینهسازی است ولی در برخی مواقع متناسب با شرایط، ممکن است از روشهای سعی و خطا نیز استفاده شود. اغلب هر اختلال قادر به تغییر کلاس یک داده خاص است و قابلیت عام بودن ندارد. اما میتوان با روشهایی اختلال عاممنظورهای[2] (همگانی) تولید نمود که پس از اعمال روی مجموعهای از دادهها موجب فریب مدل گردد [21], [22]. صورت کلی مسئله حمله به صورت رابطه (1) تبیین میشود [1], [2]:
F(x+η)≠F(x) (1
در رابطه (1)، منظور از η همان اختلال و F دستهبند یا مدل فراگرفته شده مسئله میباشد. هدف از رابطه فوق این است که در زمان ترکیب اختلال با داده اصلی، دادهای تولید شود که باعث فریب و به اشتباه افتادن مدل گردد. حال اگر مسئله بهینهسازی را با در نظر گرفتن شرایط تبیین نماییم، مسئله پیداکردن یک اختلال به صورت رابطه تعریف میشود:
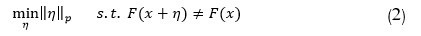
در رابطه (2)، منظور از ‖∙‖_p نرم lpمیباشد. همانطور که مشخص است؛ رابطه (2) حالت کلی مسئله بهینهسازی پیداکردن کوچکترین اختلال همراه با برقراری شرایط رابطه (1) میباشد. حملات با استفاده از ایدههای مختلف، اختلالها را پیدا میکنند.
در مقابل روشهای حمله، به کلیه فرآیندهایی که به مقابله با آسیبپذیری مدلهای هوشمصنوعی نسبت به نمونههای خصمانه میپردازند دفاع گفته میشود. این فرآیندها شامل روشهای متنوعی هستند که پاسخ مدل را نسبت به ورودی خصمانه کنترل میکنند. همچنین در برخی روشها دقت و تعمیمپذیری مدل نیز افزایش مییابد [4], [5], [12], [16], [23], [24]. روشهای دفاع و مقابله با حملات و نمونههای خصمانه به دو دسته روشهای کنشی[3] و روشهای پیشکنشی[4] تقسیمبندی میشوند [4], [25]. در روشهای کنشی پس از ساخت شبکه عصبی (مدل)، به بررسی آسیبپذیری و مقابله با نمونه خصمانه میپردازیم. در برخی روشها پس از تشخیص خصمانهبودن نمونه ورودی، آن ورودی از ادامه فرآیند خارج شده و پس از طی چند مرحله (مراحل پاکسازی) مجدداً به فرآیند عادی برگشت داده میشود. در روشهای پیشکنشی بیشتر به ماهیت شبکه عصبی عمیق توجه میشود. درواقع سعی میشود تا طراحی معماری شبکه، تابع هزینه یا بخشبندیهای مشابه بهگونهای تغییر یابند که مدل نسبت به حملات و نمونههای متنوع خصمانه مقاوم باشد.

تصویر 3: هشدار نشت دادههای یک مدل هوشمصنوعی
باتوجه به اینکه روشهای مبتنی بر شبکههای عصبی عمیق داده زیادی را نیاز دارند، از اینرو دادگان آموزشی برای هر شرکت و موسسهای که مدل هوشمصنوعی را تولید میکند مهم است. از همین جهت نوع دیگری از حملات به منظور استخراج دادههای آموزشی از یک مدل هوشمصنوعی از پیشتعلیم دیده شده نیز وجود دارد. استخراج دادههای حساس و محرمانه و یا هویتی نیز یکی از معضلات تسلیمشدن نسبت به این رویکردهای حمله است و تحت عنوان نشت حریمخصوصی نیز اطلاق میشود. لذا نیاز است که مدلهای هوشمصنوعی نسبت به این نوع از حملات نیز مقاوم باشند [26], [27].
باتوجه به اینکه در برخی مدلهای هوشمصنوعی نظیر شبکههای عصبی، قابلیت تفسیرپذیری به ندرت و با پیچیدگی زیادی وجود دارد، شناسایی یک راهحل مناسب جهت دفاع نسبت به حملات خصمانه و یا تعمیمپذیری مدل نیز تاحدی سخت و پیچیده است. این بحث تا حدی مهم است که به یک شاخه تخصصی در هوشمصنوعی به نام XAI یا eXplainable AI تبدیل شده است [28]. در تصویر 3 وضعیت تفسیرپذیری مدلهای پرکاربرد نشان داده شده است. مشاهده میشود که شبکههای عصبی با اینکه در سالهای اخیر به دقتهای بسیارخوبی در وظایف مختلف نظیر دستهبندی[5] و بخشبندی[6] و … رسیدهاند، اما از لحاظ تفسیرپذیری در مقام پایینی قرار دارند. از همینرو مجموعههای بزرگ تحقیقاتی و حتی نظامی پروژههای کلانی را روی موضوعات تعریف نمودهاند.
برای نمونه سازمان پروژههای پژوهشی پیشرفته دفاعی DARPA[7] چندین پروژه تحقیقاتی در این خصوص ایجاد کرده و سرمایهگذاری قابل توجهی بر روی آنها داشته است [29], [30].
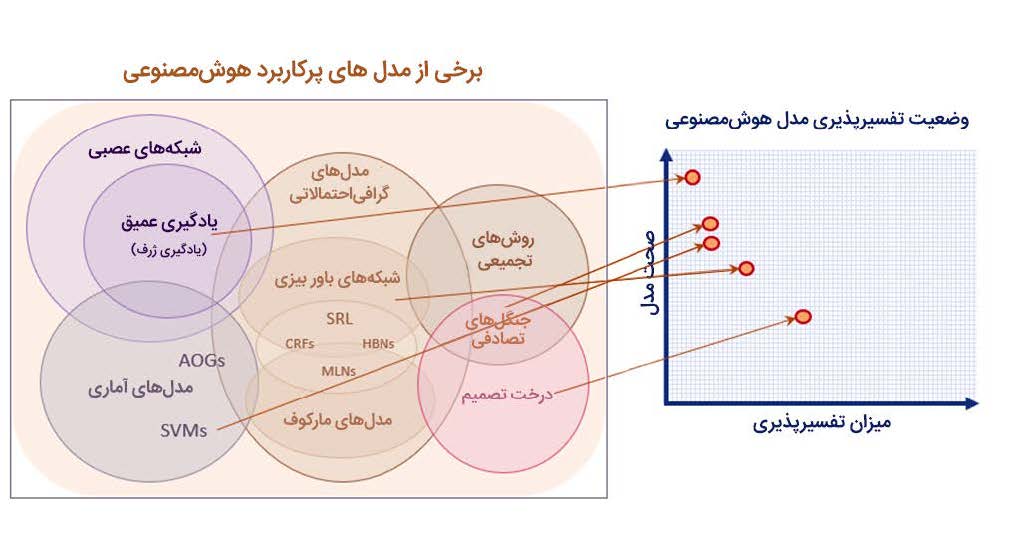
تصویر 4: نمایی از میزان تفسیرپذیری مدلهای پرکاربرد هوشمصنوعی [بهصورت اختصاصی برای مجله رصد از منبع 30، فارسی شده است]
 نظر نویسنده
نظر نویسنده
استفاده از مدلهای آسیبپذیر در فعالیتهای مختلف ارزیابی و بهخصوص امنیتی نظیر احراز هویت صوتی یا تصویری یا … میتواند مخاطرات متعددی را داشته باشد و نیاز است تا واحدهای نظارت و ارزیابی بر مدلهای هوش مصنوعی نیز در آینده نزدیک کشور ایجاد گردند. درواقع همانند محصولات غذایی، برچسب تاییدیه سطح کیفی بر محصولات هوشمصنوعی نیز زده شود.
منابع
[1] C. Szegedy et al., “Intriguing properties of neural networks,” in International Conference on Learning Representations, Dec. 2014.
[2] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” 3rd International Conference on Learning Representations, ICLR 2015 – Conference Track Proceedings, 2015.
[3] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards Deep Learning Models Resistant to Adversarial Attacks,” in International Conference on Learning Representations, Feb. 2018.
[4] A. Chakraborty, M. Alam, V. Dey, A. Chattopadhyay, and D. Mukhopadhyay, “Adversarial Attacks and Defences: A Survey,” Sep. 28, 2018. http://arxiv.org/abs/1810.00069 (accessed Aug. 17, 2019).
[5] N. Akhtar and A. Mian, “Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey,” IEEE Access, vol. 6, pp. 14410–14430, Feb. 2018.
[6] Y. Li, L. Li, L. Wang, T. Zhang, and B. Gong, “N Attack: Learning the distributions of adversarial examples for an improved black-box attack on deep neural networks,” in 36th International Conference on Machine Learning, ICML 2019, 2019, vol. 2019-June, pp. 6860–6870.
[7] F. Assion et al., “The Attack Generator: A Systematic Approach Towards Constructing Adversarial Attacks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2019. Accessed: Sep. 17, 2019. [Online]. Available: http://arxiv.org/abs/1906.07077
[8] S. Thys, W. van Ranst, and T. Goedemé, “Fooling automated surveillance cameras: adversarial patches to attackperson detection,” in Proceedings of the IEEE International Conference on Computer Vision (CVPR) Workshop, 2019, vol. abs/1904.0. [Online]. Available: http://arxiv.org/abs/1904.08653
[9] H. M. Arjomandi, M. Khalooei, and M. Amirmazlaghani, “Limited Budget Adversarial Attack Against Online Image Stream,” in International Conference on Machine Learning Workshop on Adversarial Machine Learning, 2021.
[10] Z. Yao, A. Gholami, P. Xu, K. Keutzer, and M. W. Mahoney, “Trust Region Based Adversarial Attack on Neural Networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2019.
[11] J. Su, D. V. Vargas, and K. Sakurai, “One Pixel Attack for Fooling Deep Neural Networks,” IEEE Transactions on Evolutionary Computation, vol. 23, no. 5, pp. 828–841, Oct. 2019, doi: 10.1109/TEVC.2019.2890858.
[12] S. Qiu, Q. Liu, S. Zhou, and C. Wu, “Review of Artificial Intelligence Adversarial Attack and Defense Technologies,” Applied Sciences, vol. 9, no. 5, p. 909, Mar. 2019, doi: 10.3390/app9050909.
[13] A. Kurakin et al., “Adversarial Attacks and Defences Competition,” ArXiv, vol. abs/1804.0, 2018.
[14] A. Joshi, G. Jagatap, and C. Hegde, “Adversarial Token Attacks on Vision Transformers,” Oct. 2021, Accessed: Nov. 21, 2022. [Online]. Available: http://arxiv.org/abs/2110.04337
[15] Y. Wang, W. Zhang, T. Shen, H. Yu, and F. Y. Wang, “Binary thresholding defense against adversarial attacks,” Neurocomputing, vol. 445, pp. 61–71, Jul. 2021.
[16] A. ArjomandBigdeli, M. Amirmazlaghani, and M. Khalooei, “Defense against adversarial attacks using DRAGAN,” in Iranian Conference on Signal Processing and Intelligent Systems, 2020, pp. 1–5.
[17] F. Tramèr, A. Kurakin, N. Papernot, I. Goodfellow, D. Boneh, and P. McDaniel, “Ensemble Adversarial Training:Attacks and Defenses,” International Conference on Learning Representations, May 2018.
[18] H. Zhang, H. Chen, Z. Song, D. Boning, I. Dhillon, and C. J. Hsieh, “The limitations of adversarial training and the blind-spot attack,” in Proceedings of the International Conference on Learning Representations (ICLR), 2019.
[19] Z. Che, A. Borji, G. Zhai, S. Ling, J. Li, and P. le Callet, “A New Ensemble Adversarial Attack Powered by Long-Term Gradient Memories,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04 SE-AAAI Technical Track: Machine Learning, pp. 3405–3413, Apr. 2020, doi: 10.1609/aaai.v34i04.5743.
[20] N. Papernot, P. McDaniel, I. Goodfellow, S. Jha, Z. B. Celik, and A. Swami, “Practical Black-Box Attacks against Machine Learning,” in Proceedings of the ACM on Asia Conference on Computer and Communications Security (ASIA CCS), 2017, pp. 506–519. doi: 10.1145/3052973.3053009.
[21] S. M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, “Universal adversarial perturbations,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. doi: 10.1109/CVPR.2017.17.
[22] J. Wu and R. Fu, “Universal, transferable and targeted adversarial attacks,” Aug. 29, 2019. http://arxiv.org/abs/1908.11332 (accessed Dec. 31, 2019).
[23] X. Zhang, X. Zheng, and W. Mao, “Adversarial Perturbation Defense on Deep Neural Networks,” ACM Comput. Surv., vol. 54, no. 8, Oct. 2021, doi: 10.1145/3465397.
[24] Google Brain team, “NIPS 2017: Defense Against Adversarial Attack | Kaggle.” https://www.kaggle.com/c/nips-2017-defense-against-adversarial-attack (accessed Oct. 04, 2019).
[25] X. Yuan, P. He, Q. Zhu, and X. Li, “Adversarial Examples: Attacks and Defenses for Deep Learning,” IEEE Trans Neural Netw Learn Syst, vol. 30, no. 9, pp. 2805–2824, Sep. 2019, doi: 10.1109/TNNLS.2018.2886017.
[26] L. Song, R. Shokri, and P. Mittal, “Privacy Risks of Securing Machine Learning Models against Adversarial Examples,” Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019.
[27] R. Shokri, M. Strobel, and Y. Zick, “On the Privacy Risks of Model Explanations,” Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, 2019.
[28] P. Linardatos, V. Papastefanopoulos, and S. B. Kotsiantis, “Explainable AI: A Review of Machine Learning Interpretability Methods,” Entropy, vol. 23, 2020.
[29] “Explainable Artificial Intelligence.” https://www.darpa.mil/program/explainable-artificial-intelligence (accessed Dec. 06, 2022).
[30] D. Gunning, E. S. Vorm, J. Y. Wang, and M. Turek, “DARPA ’s Explainable AI ( XAI ) program: A retrospective,” Applied AI Letters, 2021.
پینوشت
[1] Vulnerability
[2] Universal
[3] Reactive
[4] Preactive
[5] Classification
[6] Segmentation
[7] Defense advanced research projects agency




