



سیستمهای تبدیل گفتار به متن از گذشته تا کنون، موجب تسهیل برقراری ارتباط بین انسان و کامپیوتر در حوزههای متعدد بودهاند. در دهه اخیر با ورود شبکههای عصبی عمیق به این حوزه، نتایج بهدستآمده در زمینه پردازش متن و گفتار بهکلی متحول شده است و مدلهای امروزی از طریق معماریهای مبتنی بر شبکههای عصبی عمیق پیادهسازی و در چارچوبهای مختلفی برای توسعه آماده میشوند. وجود کاربردهای زیاد برای این فناوری، انگیزه شرکتهای بسیاری برای سرمایهگذاری در این حوزه بوده است. پیشبینی میشود در آینده نزدیک، فناوری بازشناسی گفتار را در اکثر اپلیکیشنهای تلفن همراه مشاهده کنیم. چرا که اپلیکیشنهایی که از این فناوری برخوردار باشند، پیچیدگی کمتری داشته و کاربران را به استفاده هر چه بیشتر ترغیب خواهند کرد.
کلیدواژهها: هوش مصنوعی، پردازش زبان طبیعی، بازشناسی خودکار گفتار، دستیارهای صوتی هوشمند، بازار جهانی سیستمهای پردازش گفتار
![]() توانایی برنامههای رایانهای برای پردازش گفتار انسان و تبدیل آن بهصورت نوشتار، بازشناسی خودکار گفتار[1] نامیده میشود. این فناوری در حوزههای متعدد و موارد گستردهای به کمک انسانها میآید. بهعنوان نمونه، افراد میتوانند به جای شمارهگیری تلفن، تنها با گفتن ارقام شماره، تماس تلفنی برقرار کنند. دستیارهای هوشمند صوتی میتوانند کنترل دیجیتال یک خانه مسکونی و یا یک خودرو را در دست گرفته و از طریق فرمانهای صوتی کاربر، شرایط مختلف خانه و خودرو را تغییر دهند. از جمله این دستیارهای صوتی میتوان به Siri اشاره کرد که توسط شرکت Apple طراحی شده است. با استفاده از Siri به راحتی میتوان در شبکههای اجتماعی مطلب منتشر کرد، واحدهای مختلف پول را فقط با صحبتکردن، به یکدیگر تبدیل کرد و محاسبات ریاضی انجام داد. علاوه بر این، دستیار صوتی گوگل امکان رزرو رستوران یا خواندن اخبار و مطلعشدن از وضعیت هوا با استفاده از فرمانهای صوتی را به کاربران میدهد. Alexa نیز یک محصول مشابه است که توسط Amazon طراحی شده است. با این دستیار میتوان کتاب صوتی گوش داد، اطلاعات لحظهای درباره وضعیت ترافیک به دست آورد و از نتایج مسابقات ورزشی بهصورت لحظه به لحظه مطلع شد [11]. تحقیقات اخیر نشان میدهد که نحوه برخورد یک دستیار صوتی در یک بانک یا در یک رستوران، میتواند حتی روی رفتار مشتریان اثر بگذارد و اینها نشاندهنده اثرات مثبت این فناوری در زندگی روزمره ما است [12]. طوری که کاربردهای گوناگون این فناوری در رفع نیازهای انسانی سبب شده تا سرمایهگذاریهای عظیمی بر روی آن انجام شود.
توانایی برنامههای رایانهای برای پردازش گفتار انسان و تبدیل آن بهصورت نوشتار، بازشناسی خودکار گفتار[1] نامیده میشود. این فناوری در حوزههای متعدد و موارد گستردهای به کمک انسانها میآید. بهعنوان نمونه، افراد میتوانند به جای شمارهگیری تلفن، تنها با گفتن ارقام شماره، تماس تلفنی برقرار کنند. دستیارهای هوشمند صوتی میتوانند کنترل دیجیتال یک خانه مسکونی و یا یک خودرو را در دست گرفته و از طریق فرمانهای صوتی کاربر، شرایط مختلف خانه و خودرو را تغییر دهند. از جمله این دستیارهای صوتی میتوان به Siri اشاره کرد که توسط شرکت Apple طراحی شده است. با استفاده از Siri به راحتی میتوان در شبکههای اجتماعی مطلب منتشر کرد، واحدهای مختلف پول را فقط با صحبتکردن، به یکدیگر تبدیل کرد و محاسبات ریاضی انجام داد. علاوه بر این، دستیار صوتی گوگل امکان رزرو رستوران یا خواندن اخبار و مطلعشدن از وضعیت هوا با استفاده از فرمانهای صوتی را به کاربران میدهد. Alexa نیز یک محصول مشابه است که توسط Amazon طراحی شده است. با این دستیار میتوان کتاب صوتی گوش داد، اطلاعات لحظهای درباره وضعیت ترافیک به دست آورد و از نتایج مسابقات ورزشی بهصورت لحظه به لحظه مطلع شد [11]. تحقیقات اخیر نشان میدهد که نحوه برخورد یک دستیار صوتی در یک بانک یا در یک رستوران، میتواند حتی روی رفتار مشتریان اثر بگذارد و اینها نشاندهنده اثرات مثبت این فناوری در زندگی روزمره ما است [12]. طوری که کاربردهای گوناگون این فناوری در رفع نیازهای انسانی سبب شده تا سرمایهگذاریهای عظیمی بر روی آن انجام شود.
 مدلهای مختلف تبدیل گفتار به متن
مدلهای مختلف تبدیل گفتار به متن
از گذشته تا کنون، سیستمهای تبدیل گفتار به متن از یک معماری کلی پیروی کردهاند. در این معماری، ابتدا ویژگیهایی از فریمهای صوتی استخراج شده و سپس این ویژگیهای متناظر فریمها به یک مدل صوتی و یک مدل زبانی، بهصورت جداگانه، بهعنوان ورودی داده میشود. هر یک از دو مدل، بر اساس دانش پیشین خود و دریافت این دنباله از فریمها، به هر دنباله از کلمات زبان یک امتیاز نسبت میدهند. امتیازات کسبشده توسط مدل صوتی و زبانی برای هر دنباله از کلمات با یکدیگر ترکیب میشود تا یک امتیاز نهایی برای رخداد آن دنباله تعیین گردد. نهایتا دنبالهای که بیشترین امتیاز را کسب کند بهعنوان خروجی نهایی سیستم اعلام میشود. در مدلهای زبانی قدیمیتر، از مدلهای آمیخته گاوسی[2]، مدلهای مخفی مارکوف[3] و قوانین ساده بیز، برای تشخیص واجهای زبان، مدلسازی توالی واجها و ارائه احتمال رخداد دنبالههای کلمات استفاده میشد [13].
پس از ورود شبکههای عصبی به این حوزه، نتایج بهدستآمده در زمینه پردازش متن و گفتار بهکلی متحول شد. با ظهور شبکههایی مانند Word2Vec، مدلسازی زبان مسیر جدیدی را آغاز کرد. تعداد کلمات قابل یادگیری و شناسایی از 10 هزار کلمه به 100 هزار کلمه افزایش یافت و بهتدریج استفاده از شبکههای عصبی بازگشتی[4] برای مدلسازی زبان و پس از آن ابداع مکانیزم توجه (Attention) جایگزین روشهای قدیمیتر شد.
مدلهای امروزی از طریق معماریهای مبتنی بر شبکههای عصبی عمیق پیادهسازی و در چارچوبهای مختلفی برای توسعه آماده میشوند. با داشتن دانش کافی و همچنین دسترسی به دادگان متنوع، میتوان به یک سیستم کارآمد دست یافت. سیستمی که بتواند منابع مختلف صدا و گویندگان متفاوت را از یکدیگر تشخیص داده و اگر آنها بهصورت همزمان صحبت کردند، کلمات بیانشده توسط هر یک از آنها را تعیین کند. سیستمی که بتواند با ویژگیهای خاص گوینده و همچنین مشخصات مخصوص یک محیط خود را وفق دهد. به عبارت دیگر، تفاوتهای ذاتی صدای دو شخص از جمله تمرکز فرکانسی مختلف، لهجه، سن گوینده، شرایط روحی گوینده و سرعت ادای کلمات توسط گوینده نباید تاثیری بر روی خروجی نهایی سیستم داشته باشد [13].
رقابت بزرگترین شرکتها برای توسعه فناوری تشخیص گفتار
به گزارش وبسایت Meticulous Research، بازار جهانی سیستمهای پردازش گفتار تا سال 2025 نسبت به سال 2019 به میزان متوسط سالانه 17.2 درصد رشد کرده، بهگونهای که ارزش آن از 10.34 میلیارد دلار فعلی به 26.79 میلیارد دلار خواهد رسید [1]. گزارشی مشابه از Grand View Research از این تخمین نیز فراتر رفته و ارزش این بازار در سال 2025 را 31.82 میلیارد دلار پیشبینی میکند [2].
در دو دهه اخیر، شرکتهای بزرگی روی گسترش فناوری تشخیص خودکار گفتار و تبدیل آن به نوشتار سرمایهگذاری کردهاند. به طور مثال، شرکت Nuance در حال حاضر محصولات بازشناسی گفتار و هوش مصنوعی خود را با تمرکز بر خدمات ابری، سیستمهای جاسازیشده، سیستمهای فرمانبر تلفنی، سیستمهای خودکار هدایت تماسها و سیستمهای پردازش گفتار مورد نیاز حوزه پزشکی ارائه میکند. لازم به ذکر است که اخیرا شرکت Nuance به ارزش تقریبی 19 میلیارد دلار توسط مایکروسافت خریداری شده است [3].
آمارهای سال 2018 که از طریق یک نظرسنجی توسط شرکت VoiceBot از جوانان آمریکا تهیه شده است، نشان میدهند که شرکتهای آمازون، گوگل و اپل با دارابودن به ترتیب 64.6، 19.6 و 4.5 درصد از سهام بازار بازشناسی گفتار، این بازار را به تسخیر خود درآوردهاند. برخی منابع عنوان کردهاند که آمازون برای رسیدن به این برتری، قریب به 10 هزار نفر را تنها مشغول به توسعه دستیار صوتی خود یعنی Alexa کرده است [4]. همچنین، گزارش Smart Audio حاکی از آن است که در سال 2018، تعداد خانههایی در آمریکا که مجهز به فناوری فرمانپذیری صوتی هوشمند هستند، با رشدی 78 درصدی نسبت به سال 2017، به 118.5 میلیون مورد افزایش پیدا کرده است. گزارشی دیگر از Recode نشان میدهد که افراد عمدتا برای گوشدادن به موسیقی، اطلاع از پیشبینی وضعیت آبوهوا و یا جستوجو در اینترنت از این سیستمها استفاده میکنند [5].
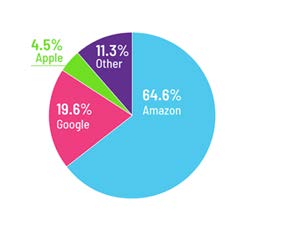
شکل 1: سهم شرکتها از بازار صنعت بازشناسی گفتار در سال 2018 در ایالات متحده آمریکا
دستیار صوتی گوگل که با نام Google Assistant شناخته میشود، قادر به تشخیص گفتار انسان و تبدیل آن به متن در 125 زبان زنده دنیاست. لازم به ذکر است که زبان فارسی نیز در این فهرست قرار دارد. متاسفانه شرکت گوگل جزئیاتی از توسعه این فناوری برای زبان فارسی منتشر نکرده است. بررسیهای سال 2020 نشان میدهد حدود 500 میلیون کاربر از این دستیار صوتی استفاده کردهاند[6]. بهصورت خاص، گوگل تلاش خود را در زمینه بازشناسی گفتار بر فراهمسازی بستر استفاده از آن در خانههای هوشمند متمرکز کرده است.
شرکت اپل، دستیار صوتی خود را که Siri نام دارد، در سال 2010 از یک استارتآپ با همین نام به ارزش 200 میلیون دلار خریداری کرد. با استفاده از Siri کاربران میتوانند برای مثال ایمیل خود را چک کنند، پیامک بفرستند، برای بیدارشدن در یک ساعت خاص زنگ بگذارند و یا اطلاعات مربوط به مسابقات ورزشی را دریافت کنند. توسعهدهندگان اولیه این محصول، حدودا با یکدهم هزینه اپل برای خریداری آن، Siri را به وجود آورده بودند و به همین جهت محصول آنها مورد ستایش اپل قرار گرفت. گزارشها نشان میدهند که 395 میلیون کاربر جدید در فاصله سالهای 2015 تا 2020 به استفادهکنندگان از Siri ملحق شده و مجموعا این دستیار صوتی توسط 660 میلیون نفر استفاده شده است. این افزایش کاربران میتواند به دلیل افزایش دقت عملکرد Siri در تشخیص گفتار باشد که از 66 درصد در سال 2017 به 87 درصد در سال 2020 رسیده است [7].
علاوه بر این، شرکت IBM نیز از مدتها پیش به دنبال توسعه فناوری بازشناسی هوشمند گفتار بوده است. اولین سیستم بازشناسی گفتار این کمپانی در سال 1962 طراحی شد که تنها قادر به شناسایی 16 کلمه بود. در سال 1996 سیستمی توسط همان گروه از محققین توسعه داده شد که توانایی تشخیص 42000 کلمه در زبانهای انگلیسی و اسپانیایی را داشت و همچنین میتوانست خطا در نگارش 100 هزار کلمه را نیز تشخیص دهد. تحقیقات IBM نشان میدهد که ارزش این بازار تا سال 2025 به 24.9 میلیارد دلار خواهد رسید [8].
سرعت سرمایهگذاری در این حوزه نیز همانند سرعت توسعه آن بسیار بالاست. برای مثال، شرکت Verbit که به طور خاص در حوزه یادگیری ماشین و پردازش زبان طبیعی فعالیت میکند، در یکماهه اخیر 157 میلیون دلار بودجه به توسعه فناوری تبدیل گفتار به متن اختصاص داده است. به گفته مدیرعامل این شرکت، دقت مدلهای آنها در تشخیص متن متناظر گفتار انسان، حدود 99 درصد است و ادعا شده از استانداردی که در صنعت وجود دارد نیز 10 برابر سریعتر عمل میکند [9].
آینده صنعت بازشناسی گفتار
پیشبینی میشود در آینده نزدیک، فناوری بازشناسی گفتار را در اکثر اپلیکیشنهای تلفن همراه مشاهده کنیم. چراکه طبیعیترین راه برقراری ارتباط انسان با گوشیهای هوشمند از طریق صحبتکردن خواهد بود. اپلیکیشنهایی که از این فناوری برخوردار باشند، پیچیدگی کمتری داشته و کاربران را به استفاده هر چه بیشتر ترغیب خواهند کرد. بدینترتیب حتی اگر کاربر اطلاع دقیقی از نحوه کار با اپلیکیشن نداشته باشد، کماکان میتواند با صحبت کردن با آن خدمت مورد نظر خود را پیدا و از آن استفاده کند. در واقع، میتوانیم به زودی شاید جایگزینی واسط کاربری گرافیکی[5] با واسط کاربری صوتی[6] در عمده گوشیهای هوشمند باشیم.
در سال اخیر با توجه به شیوع ویروس کرونا، دستیارهای صوتی نقش موثری در بررسی وضعیت بیماران و علائم آنها ایفا کردهاند. به طور مثال، بعضی از رباتهای سخنگو مانند Siri توانستند با مطرحکردن سوالاتی از کاربران، به آنها پیشنهادهایی در جهت بهبود وضعیت سلامتیشان ارائه کرده و از بار جامعه پزشکی تا حدی بکاهند. از طرفی، دسترسی افراد به این گونه دستیارها بسیار سادهتر و امنتر از دسترسی به بیمارستانها در زمانهای اوج شیوع است.
علاوه بر این، به کمک یادگیری ماشین و پردازندههای گرافیکی، در سالهای آینده صداهای مربوط به این رباتهای سخنگو طبیعیتر جلوه خواهند کرد. به طوری که احساسات نیز در بیان جملات توسط آنها در نظر گرفته خواهد شد. از همین فناوری میتوان در جهت بهبود کیفیت صدا و کنترل لحن بیان آن برای استفاده در صنعت سینما و تبلیغات نیز بهره برد. مثلا ممکن است یک بازیگر، متنی را با احساس کافی بیان نکند. در این مواقع، سامانه رایانهای با ایجاد تغییرات مورد نظر کارگردان، از تکرار فیلمبرداری جلوگیری کرده و روند انجام کار را تسهیل میکند. در صنعت بازیسازی نیز بهجای ضبط و پخششدن صدای کاراکترهای بازی، میتوان با استفاده از شبکههای عصبی بهصورت بلادرنگ صدا تولید کرد. در واقع توانایی تقلید صدای انسان بهعنوان یکی از جذابترین کاربردهای بازشناسی و تولید گفتار در صنعت تولید بازیهای کامپیوتری مطرح است.
همچنین، دستیارهای صوتی قادر خواهند بود همزمان به اهالی خانه بر حسب نیازشان سرویسدهی کنند. مثلا اگر فرزند خانواده از دستیار صوتی سوال «امروز چه کارهایی باید انجام بدهم» را بپرسد، جوابی که دستیار صوتی به او میدهد، متفاوت با جوابی خواهد بود که به پدر خانواده خواهد داد. زیرا این دستیارها خواهند توانست بهخوبی تفاوت میان صدای اشخاص را درک و متناسب با شخصی که درخواست را مطرح کرده، پاسخ را شخصیسازی کنند. در مثالی که ذکر شد، دستیار صوتی میتواند به پدر، تقویم کاری و به فرزند، تقویمی شامل برنامهریزی درسی او را نشان دهد.
یکی دیگر از کاربردهای فناوری بازشناسی گفتار، در صفحهنمایشهای مخصوصی است که در خانههای هوشمند بهکار گرفته میشوند. این صفحهنمایشها گاهی توانایی تشخیص چهره را نیز دارند. از جمله این محصولات میتوان به Russian Sber portal و smart screen Xiaodu اشاره کرد که محصولات کشورهای روسیه و چین هستند[10] . شایان توجه است که این صفحهنمایشها قابلیتهای متعددی دارند. به طور مثال حرکات چشم انسان را تشخیص میدهند و در زمینه بازشناسی گفتار بهاندازهای قدرتمند هستند که میتوانند حتی از فاصلههای دور، صداها را با وضوح دریافت کرده و متن متناظر آنها را به دست آورند.
نتیجهگیری
با توجه به کاربردهای متعدد فناوری بازشناسی و تولید گفتار و تحلیلهای منتشر شده، در سالهای پیشرو شاهد دگرگونی عظیمی در استفاده از ابزارهای الکترونیکی خواهیم بود و جهان اطراف ما دچار تغییرات عمدهای خواهد شد. تکنولوژی بازشناسی و تولید گفتار، سهم بیشتری را در زندگی یکایک ما ایفا خواهد کرد و همگان خواهند توانست از مزایای آن بهرهمند شوند.
منابع
[1] https://meticulousblog.org/top-10-companies-in-speech-and-voice-recognition-market/
[2] https://www.grandviewresearch.com/industry-analysis/voice-recognition-market
[3] https://www.computerweekly.com/news/252499249/Why-Microsofts-19bn-acquisition-of-Nuance-makes-sense
[4] https://hbr.org/2019/05/why-tech-giants-are-so-desperate-to-provide-your-voice-assistant
[5] https://www.cbinsights.com/research/facebook-amazon-microsoft-google-apple-voice/
[7] https://www.businessofapps.com/data/apple-statistics/
[8] https://www.ibm.com/cloud/learn/speech-recognition
[10] https://clearbridgemobile.com/7-key-predictions-for-the-future-of-voice-assistants-and-ai/
[11] Hoy, M. B. (2018). Alexa, Siri, Cortana, and more: an introduction to voice assistants. Medical reference services quarterly, 37(1), 81-88.
[12] Poushneh, A. (2021). Humanizing voice assistant: The impact of voice assistant personality on consumers’ attitudes and behaviors. Journal of Retailing and Consumer Services, 58, 102283.
[13] Palaz, D., Magimai-Doss, M., & Collobert, R. (2019). End-to-end acoustic modeling using convolutional neural networks for HMM-based automatic speech recognition. Speech Communication, 108, 15-32.
پاورقی
[1] Automatic Speech Recognition
[2] Gaussian Mixture Model (GMM)
[3] Hidden Markov Model (HMM)
[4] Recurrent Neural Network (RNN)
[5] Graphical User Interface (GUI)
[6] Voice User Interface (VUI)




